위 영상을 번역 및 요약한 것입니다.
보다가 모르는 내용은 맨 하단에 링크로 덧붙일 예정입니다.
GPU crashes are hard
CPU crash는 디버그하기 쉽다 - 크래시가 발생하는 즉시 크래시 리포트가 발생하고, 모든 스레드가 중단되며, 크래시 당시의 프로그램 상태를 바로 살펴볼 수 있다.
CPU에 비해서 GPU는 동시에 여러 개의 스레드가 실행되고 있기 때문에, 크래시가 일어난 지점으로 돌아가는 데 시간이 걸린다. 따라서 GPU 크래시 리포트는 실제 크래시가 일어난 시점으로부터 더 나중에 - 2초 또는 그 이상 이후에- 보고되게 된다.
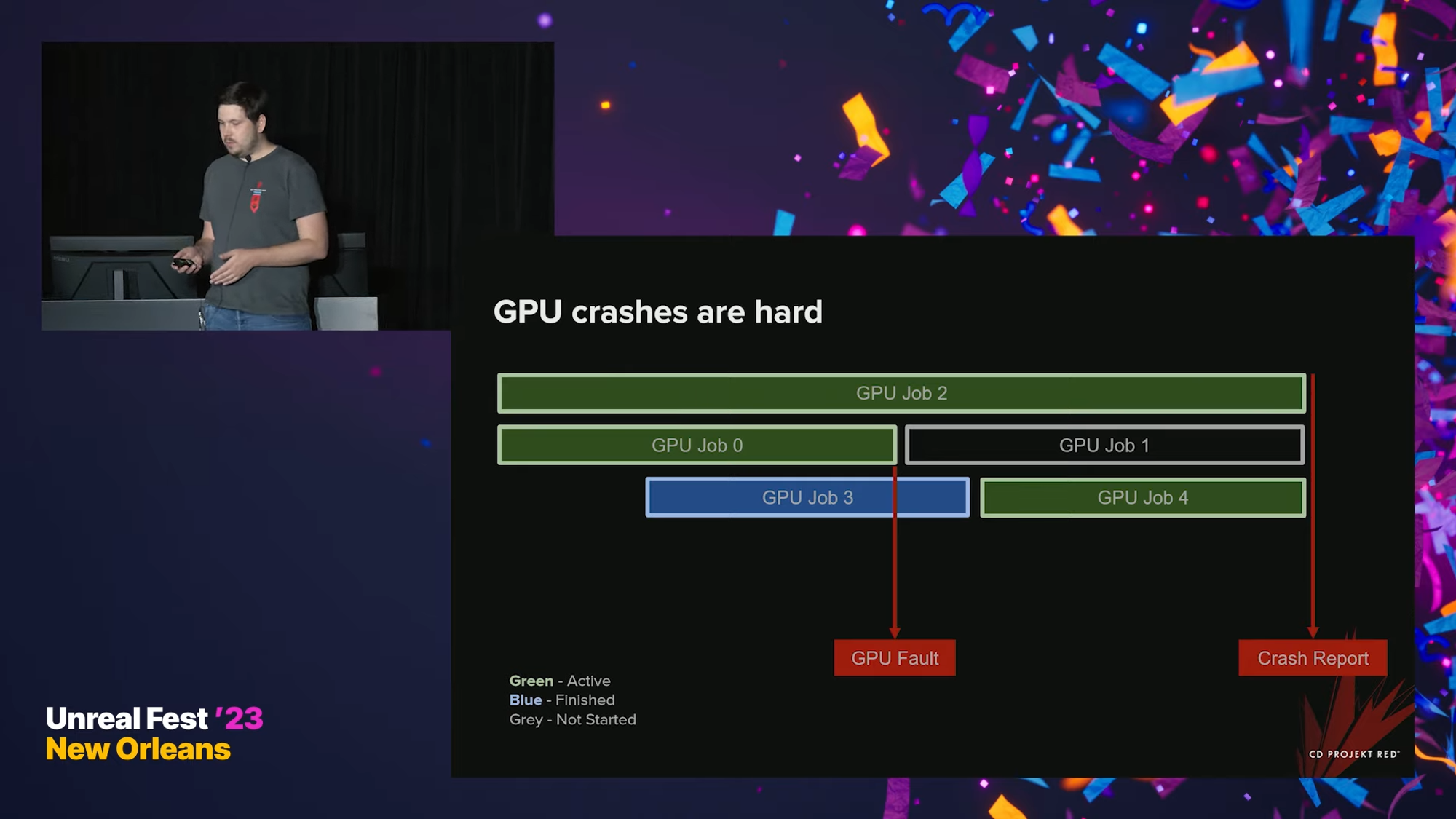
크래시 당시에 시작되지도 않은 job이 보고되거나, 이미 끝난 job이 보고될 수도 있다. 그렇게 되면, 실제 어느 job이 gpu에 크래시를 발생시켰는지 알 방법이 없다.
Windows TDR
TDR은 Timeout Detection and Recovery의 약자로, GPU가 중단되어 프로그램의 실행을 멈추어야 할 경우 작동되는 윈도우 시스템이다. 이 상황을 timeout이라고 하는데, 이 상황이 발생하면 GPU는 리셋되고 크래시를 수행한다.

- GPU Crash가 생길 수 있는 또다른 원인은 page fault 이다.
이것은 유효하지 않은 메모리 접근이 있었다는 것이고, CPU단의 Access Violation 또는 null pointer exception과도 같은 것이다. - timeout이 발생하는 가장 명확한 원인은 무한한 loop 이다 - 끝나지 않는 셰이더 이다. 이것은 GPU를 멈추게 한다.
- 또 다른 원인은 부정확한 동기화(Incorrect Synchronization) 이다. GPU가 wait 하라고 지시받았지만, continue하라는 신호를 받지 않았을 경우, 작동을 멈춘다. 아주 느린 셰이더 - 특히 RayMarching이나 RayTracing도 GPU를 멈추게 할 수 있다. 작업을 완료하는 데 오래 걸리는 셰이더도 TDR를 발생시킬 수 있다 - 셰이더가 마침내 끝나게 되어 있더라도 말이다.
- 물리적인 메모리가 부족한 상황에서도 GPU가 크래시 될 수 있다. Swapping이 필요할 경우, 모든 작업이 아주 느려지고, 크래시가 날 수 있다.
- 드라이버에 버그가 있어 timeout이 생기는 경우도 있다. 이 경우에도 같은 에러가 나올 것이다.
동기화 버그에 대해 좀 더 알아보자. Witcher 3에서 우리는 이상한 동기화 버그가 있었다. 아주 복잡하지는 않았지만, 이상한 점은 TDR이 발생하지 않았다는 것이다. 결국 TDR이 없는 것 처럼 프로그램이 영원히 freeze하게 되었다. 우리는 GPU에 커스텀 커맨드들을 사용해서 왜 멈추는지 직접 살펴보아야 했다.
또 다른 Timeout은 시네마틱에 있었다. 시네마틱 팀에서 시퀀서를 사용할 때 크래시가 발생했고, 한 프레임 당 몇 초가 소요되었고, 원인은 그들이 가장 높은 퀄리티와 무한한 View Distance를 사용했기 때문이었다. 이것은 당연히 TDR를 발생시켰다 - 렌더링에 여러 초가 소요되고 이것은 오프라인 렌더링에 적합하지 않았기 때문이다. (?)
이것을 고치기 위해 우리는 단순하게 TDR Delay를 늘려주었다. 오프라인 렌더링에서는 그 정도 오래 걸리는 것은 GPU 에 괜찮기 때문이었다. 하지만 당신이 실시간 렌더링을 사용하고 있다면 이 방법은 사용할 수 없다. - 오프라인 렌더링에서만 이 방법을 사용해 볼 것을 권장한다.
이제 Page fault를 살펴보자. DX12에서는 아주 정교한 메모리 관리를 할 수 있게 되었지만, 이것은 또한 유효하지 않은 메모리 접근에 대한 위험을 야기하였다. 만약 퇴출된(evicted) 리소스에 대한 주소에 접근했을 경우, GPU가 크래시된다. 실제 fault가 일어난 시점과 크래시 리포트 사이에 아주 긴 딜레이가 생길 수 있음에 주의하는 것이 좋다.
Page Fault
https://terms.naver.com/entry.naver?docId=858196&cid=50371&categoryId=50371
페이지 틀림
접근하고자 하는 데이터나 프로그램이 현재 주기억 장치에 존재하지 않기 때문에 디스크로부터 읽어 들여야 할 경우에 일어나는 중단.
terms.naver.com
https://blog.naver.com/ki_dongg/223234061687
[컴퓨터과학]가상 메모리(Demand Paging, Page Fault, Page Replacement, Caching)
Demand Paging은 프로그램이 필요한 것을 요청할때마다 paging을 하는 방법이다. Page Fault는 프로그...
blog.naver.com
프로그램이 요청하는 Page가 메모리에 없을 때의 상황을 의미한다.
아래는 우리가 PS5에서 겪은 Page fault 사례이다.
GPU 크래시가 났을 때, 특정 머그잔의 머터리얼 1개에서 발생했다는 것을 추적해낼 수 있었다. 이 머그잔에서는 아주 복잡한 머터리얼을 사용했고, 여러 장의 Virtual Texture들을 샘플링하고 있었다. 좋은 단서는 우리가 막 엔진을 업데이트 한 이후였다는 것이다 - 많은 피쳐들이 아직 개발중이었고, 원인이 Virtual Texture이라는 것을 발견했다. 우리는 제 2의 해결책을 찾고, Virtual Texture관련 이슈를 해결할 다음 엔진 패치까지 기다렸다.. 그리고 이슈가 해결되었다.
이제 GPU 크래시에 대해 알았으니, 이제 이러한 이슈들에 어떻게 접근하고, 이슈 해결을 위해 Unreal Engine안팎에서 어떤 도구들을 사용할 수 있는지 살펴보도록 하자.
아쉽게도, GPU 크래시를 디버깅하는 과정은 CPU 쪽에 비해 그다지 문서화가 잘 되어 있지는 않다,
Sanity Check
- 드라이버가 업데이트 되어있는지 확인
→ 이것이 크래시를 발생할 경우, 이 이슈에 대해 탐색하는 것은 시간 낭비이다. - 충분한 능력의 GPU를 사용하고 있고, 메모리가 충분한지 확인
→ 특히 언리얼의 새로운 피쳐들, 그리고 RayTracing과 같은 새로운 피쳐들을 사용할 때 GPU가 적절한 세팅을 감당할 수 있는지 확인한다. - 에디터에서는 특히 더 무겁다 - 퀄리티 셋팅을 확인하고, 월드 전체가 메모리에 동시에 존재하지는 않는지 확인한다.
→ 리소스가 없어 GPU가 크래시 날 수 있다. - offline render 등의 무거운 백그라운드 프로세스가 실행 중인지 확인한다.
Unreal에서 GPU Debugging 하기
-gpucrashdebugging
: 커맨드 라인 argument. gpu 에서 무슨일이 일어나고 있는지 추적하는 데 필요한 기능들을 활성화.
오버헤드가 있기 때문에 디폴트로 비활성화 되어 있다.
- -d3ddebug
추가적인 validation을 원한다면 GPU Validation Flag를 사용한다. 크래시를 유발하는 잘못 만들어진 d3d 커맨드가 있는지 검증하는 데 유용하다. 그러나 이 검증 (validation)은 CPU에서 일어난다는 점을 기억하자. GPU에서는 검증 과정이 없기 때문에, 특정한 에러를 테스트해볼 수는 없다. - 정보를 다 가지고 있는 것은 아니기 때문에.
에러를 잡아내기 위한 빠르고 손쉬운 방법이다. - -gpuvalidation
셰이더가 추가적인 체크를 하도록 한다. CPU에서 발견해낼 수 없는 에러들을 잡아낼 수 있다. 부정확한 descripter나 참조, 삭제된 리소스와 descripter heap 이후의 인덱싱도 찾아낼 수 있다. (?) 이 모든것이 page fault를 야기한다. - 또 다른 유용한 도구는, 추가적인 이벤트들을 활성화 하는 것이다.
r.EmitMeshDrawEvents 1
r.Nanite.ShowMeshDrawEvents 1
r.ShowMaterialDrawEvents 1
정확히 어느 머터리얼 또는 메시가 GPU Crash를 일으키는 지 알려면, mesh 와 material의 draw event를 활성화 하면 좋다. 이것은 크래시 디버깅과 프로파일링을 위한 각 드로우 콜의 information을 포함할 것이다. 다만, 큰 퍼포먼스 비용이 든다는 것에 유의하자. GPU Profiler상에서도 잘 작동한다. 앞에서 언급한 머그잔 이슈의 경우도 mesh event를 활성화해서 쉽게 추적해 낼 수 있었다.
page fault의 경우에 할당에 대해 더 많이 알아낼 수 있는 cvar이 있는데, 앞에서의 -gpucrashdebugging을 사용하면 자동으로 활성화 된다. (D3D12.TrackAllAllocations)
만약 크래시에서 리포트 된 리소스가 아주 많지 않다면, 이 cvar를 활성화 해 볼 수 있다 - GPU에 할당된 모든 리소스들을 추적해 준다.
아래는 page fault address에 기반해서 언리얼 엔진이 활성화 된 리소스 목록을 출력해 준 예시이다.

fault address 주변의 16 MB 범위를 포함하며, 이것은 out-of-bound access 를 찾아내는 데 도움을 줘, 리소스의 끝 부분 너머를 인덱싱하고 있지 않은 지 알 수 있다.
언리얼은 또한 지난 100프레임동안 헤재된 리소스들을 추적하는데, 앞에서 본 활성화 된 리소스들과 비슷하게 리포트되지만, 아래 이미지처럼 page fault address와 정확히 일치하는 리소스들만 리포트 된다.

이제 GPU Crash 디버깅 플래그가 어떤 일을 하는 지 좀더 깊이 살펴보자.
우선, CPU Stack은 쓸모있는 정보를 전혀 제공하지 못한다. GPU에 스케쥴링된, 크래시를 유발한 커맨드는 아주 예전에 스케쥴링 된 것이다. 우리는 크래시 당시의 GPU의 정확한 상태를 알아야 한다 - 이렇게 하는 방법에는 아주 여러 가지가 있는데, 플랫폼마다 각자 방법이 다르다.
PC부터 시작해보자. PC에서 쓸 수 있는 여러 가지 Tool 들이 있다. 첫 번째 툴은 DRED라고 불린다 - Device Removed Extended Data 의 약자이다. 여기에는 방대한 추가적인 정보가 포함되어 있고, 윈도우즈에서 핸들링된다. 그리고 Breadcrumbs가 있다 - 이것은 DREDS와 매우 비슷하지만, 사용자가 직접 구현한다. NVIDIA와 AMD GPU에서는, NVidia AfterMath 또는 Radeon GPU Detective 같은 전문 도구를 사용할 수 있다.
콘솔에서 사용할 수 있는 도구들은 플랫폼별로 매우 세분화되어 있다. 크래시가 나면, Dump를 볼 수 있고, GPU의 상태를 상세히 살펴볼 수 있다. 보통은 PC에서 더 많은 정보를 얻을 수 있다. 그래서 만약 콘솔에서 디버깅을 하고 싶다면, PC에서 돌려볼 것을 추천한다.
첫 번째 도구인 DRED부터 살펴보자. DRED는 사용하기 편리하고, DirectX 12 지원 하드웨어에서도 작동하며, 언리얼에서도 이미 지원하고 있다. DRED는 모든 렌더 작업 이후 마커를 삽입한다. 모든 과정이 자동이고, 사용자가 제어할 수 있는 부분은 거의 없다.
하지만 최근 언리얼에서 경량 DRED에 대한 지원을 추가했다. 이것은 추적할 수 있는 렌더 작업도 더 적은 대신, 오버헤드도 더 적기 때문에 기본 값으로 활성화해두기 쉽다. 아래는 크래시 당시에 DRED가 보고한 커맨드 리스트의 예이다.
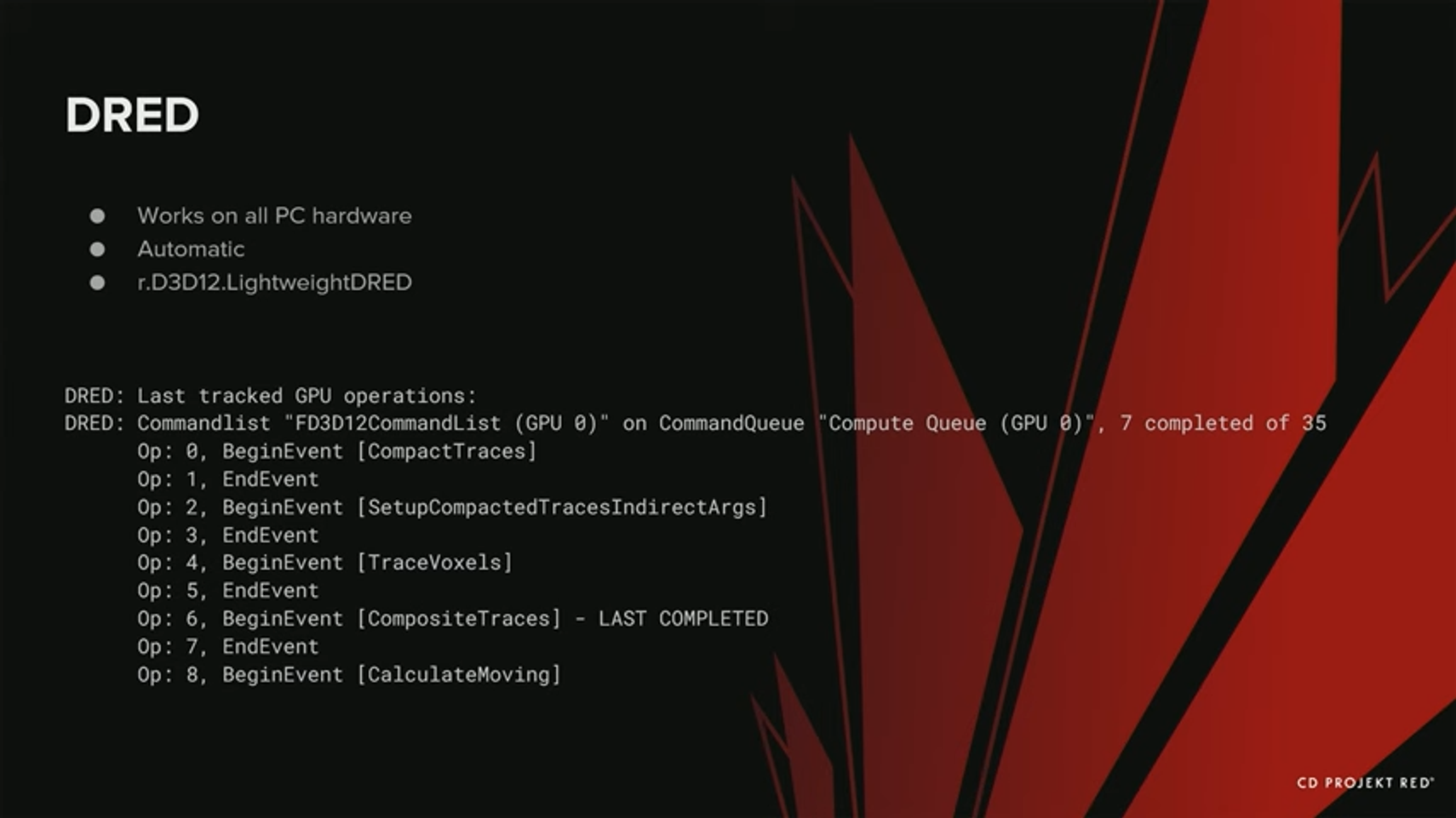
보이는것처럼, 크래시 당시 6 또는 7개의 작업이 완료되었음을 알 수 있다. 그러나 이런 복합적인 trace가 크래시가 일어난 지점이라고 보장하는 것은 아니다.
앞서 말한 것처럼 DRED는 Device Removed Extended Data 이다 - 여기에서 Data에는 Page Fault Data도 포함하는데, 이 정보는 아주 유용하다. Page Fault가 일어난 주소를 알 수 있고, Unreal처럼 최근에 사용되거나 헤재된 리소스들을 추적하는데, Unreal처럼 16MB 범위만 추적하지는 않는 점이 다르다.
참고 : D3D12 DRED
https://microsoft.github.io/DirectX-Specs/d3d/DeviceRemovedExtendedData.html
D3D12 Device Removed Extended Data (DRED)
Engineering specs for DirectX features.
microsoft.github.io
아래는 DRED가 보고한 page fault 당시의 리포트이다.

보이는 것처럼, page fault 가 일어난 가상 주소 범위 내의 활성화 상태인 오브젝트와 최근에 해제된 오브젝트들의 리스트를 보여준다.
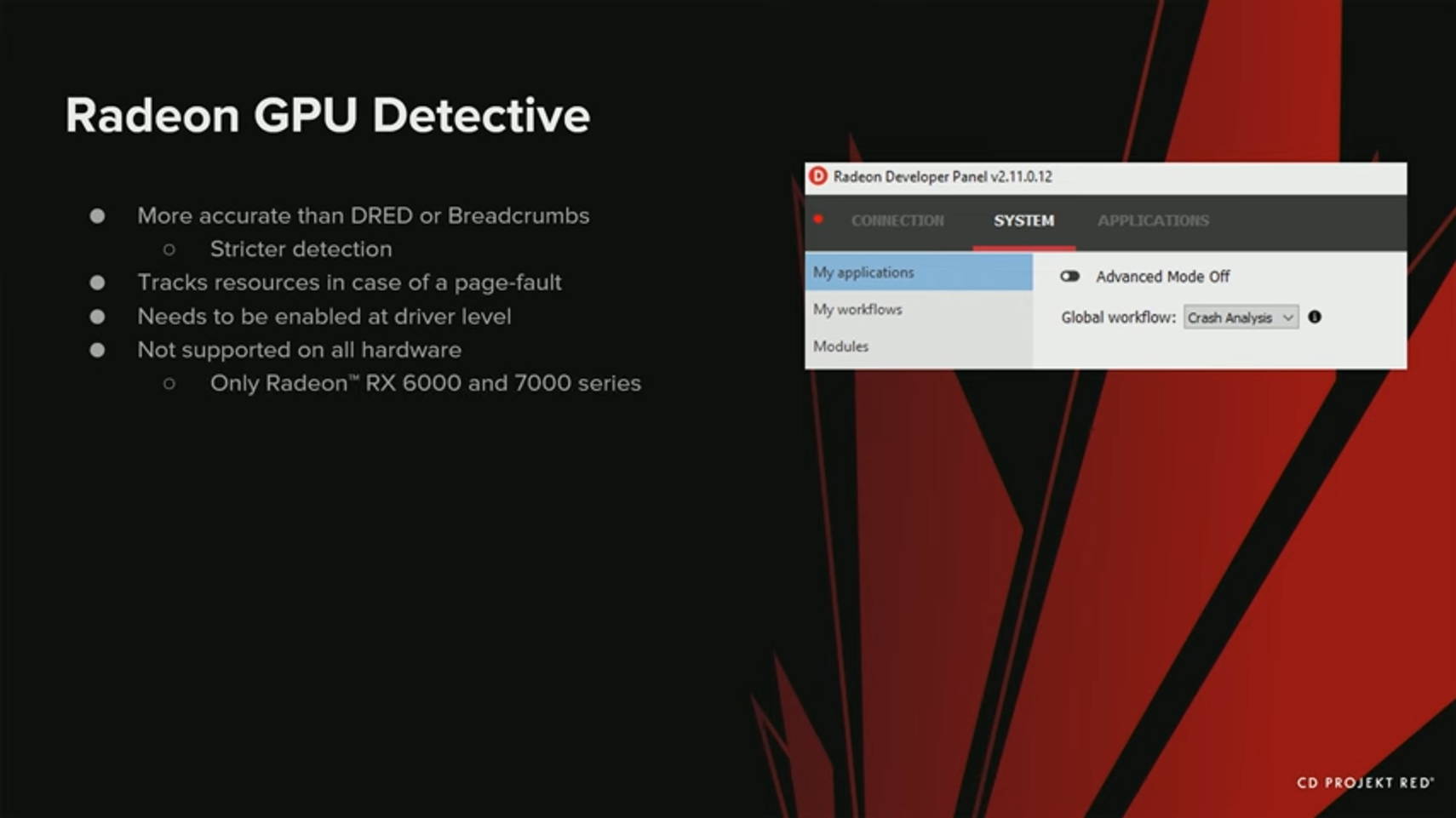
이제 Radeon GPU Detective를 살펴보자. Radeon Detective는 DRED나 Breadcrumbs보다 더 정확하다. Detection이 더 엄격해서, 드라이버가 더 일찍 크래시하고, 더 많은 정보를 포함하도록 지시한다.
page fault인 경우에는 리소스도 추적한다. 하지만, 크래시 분석 모드를 동작해서 더 많은 정보를 얻기 위해 특별한 모드가 필요하기 때문에, 드라이버 단에서 활성화 해야 한다.
모든 장치에서 사용 가능한 것은 아니고, AMD 비디오 카드들, 그중에서도 최신 RX 6000 과 7000 시리즈에서만 활성화 할 수 있다.
이제 NVidia Aftermath로 넘어가자. NVidia Aftermath는 Radeon GPU Detective와 동일한 것인데, 언리얼에 이미 통합되어 있다. TDR시 dump를 만들어 나중에 살펴볼 수 있게 한다. DRED나 Breadcrumbs에서도 볼 수 있는 GPU 에 대한 정보를 보여준다. 레지스터 값과 활성화 된 warp들을 보여주기 때문에, NVIDIA GPU에서 더 심화된 크래시를 잡는 데 도움이 될 수 있다. 다른 툴들처럼 가상 주소를 추적할 수 있는데, nvidia aftermath를 포함한 채로 출시할 수 있는 점이 다르다. (원문 : you can ship with with NVIDIA Aftermath)
NVIDIA Nsight Aftermath for GPU Pipeline Debugging
Integration of NVIDIA Nsight™ Aftermath C++ library that enables post-mortem GPU crash analysis on NVIDIA GPUs.
docs.unrealengine.com

마지막으로 언리얼의 Breadcrumbs를 살펴보자. Breadcrumbs는 위 세 가지 툴의 유저 구현 버전이다. 어떤 마커를 언제 사용할 지, 거기에 어떤 정보를 저장할 지 모두 수동으로 설정해 주어야 한다. DRED도 이것과 비슷하지만, 사용자에게 더 적은 컨트롤을 제공한다. 그리고 사실은, 더 진보된 버전의 Breadcrumbs가 언리얼에 곧 포함된다고 한다.
최초 구현된 이전 버전의 Breadcrumbs를 살펴보자. 약간의 단점들이 있다 - 오리지널 Breadcrumbs는 최후에 시작되거나 완료된 마커만 보고하기 때문에, 알 수 있는 정보가 많지 않고, 경우에 따라 부정확할 수도 있다.
예시를 한번 보자. 여기에서 우리는 부정확한 Breadcrumbs report를 명확히 확인할 수 있다.
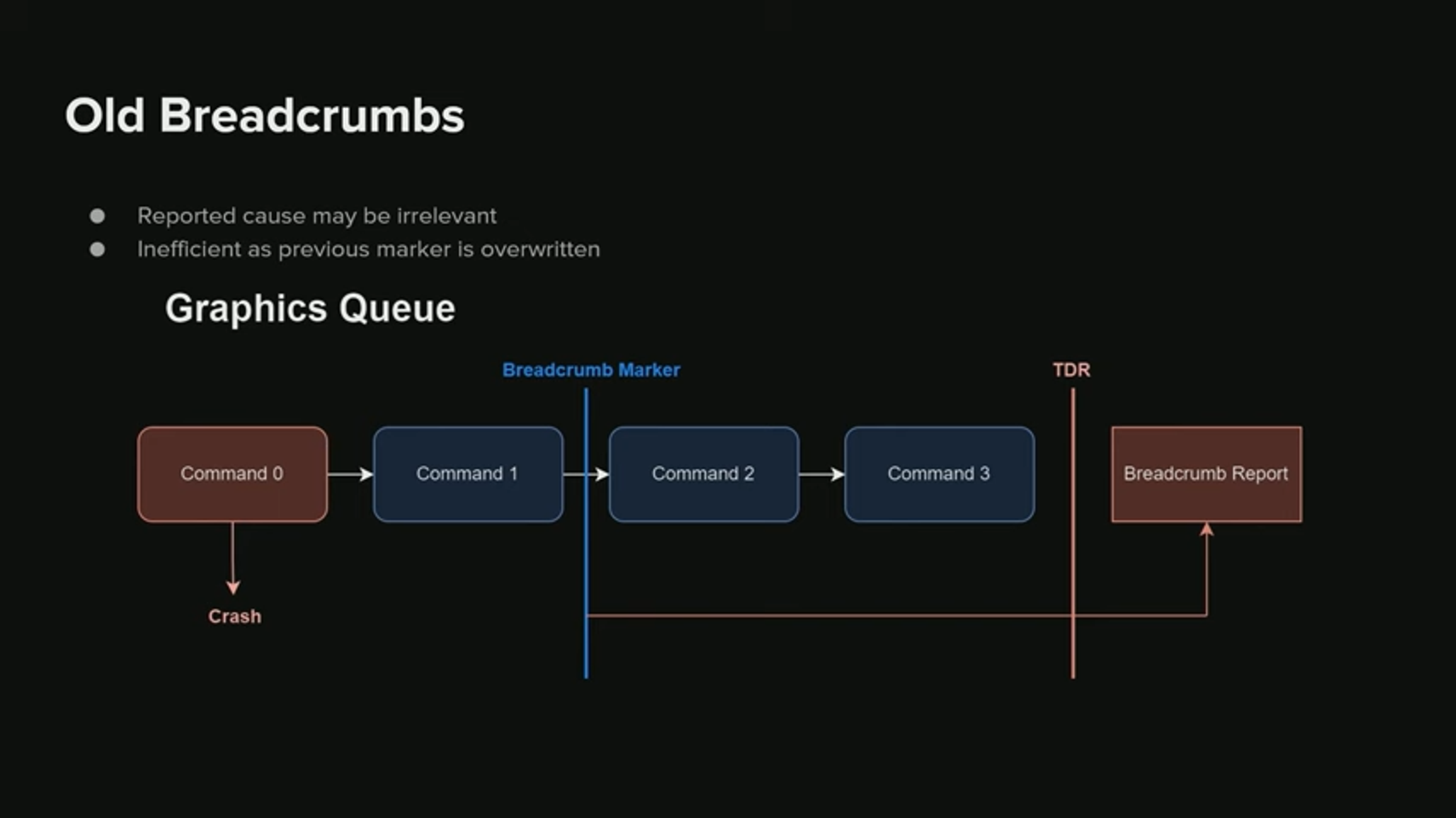
만약 command 0 가 크래시를 발생시키고, TDR이 일어났을 때 보고를 받지만, Breadcrumbs는 맨 마지막 마커만 보고한다. 따라서 이 마커는 command 1 이후일 것이다. 따라서 우리가 얻는 정보에서는 command 1이 크래시와 관련이 있다고 되고 있게 된다. 이 경우 이것은 우리를 헷갈리게 만든다. 크래시의 종류에 따라, 실제 보고까지의 시간은 크게 차이날 수 있다.
New BRRS
새로운 Breadcrumbs를 살펴보자.. 우리는 이것을 RED Engine으로부터 언리얼로 포팅해 왔고, Github에서 사용 가능하기 때문에 이미 엑세스 권한이 있을 수 있다.
새로운 Breadcrumb는 GPU 전 범위를 더 큰 buffer로 추적한다. 다시 이전 예시로 돌아가보자.

여기에서는 command 2가 크래시를 발생시킨다. 하지만 우리는 여러 개의 Breadcrumb가 있다 - Breadcrumb marker A와 B가 있기 때문에,
TDR이 일어났을 때 보고를 받을 때 모든 활성화된 Breadcrumb들과 그것과 관련된 상태들을 전달받는다.
새로운 breadcrumb들이 어떻게 생겼는지 살펴보자.
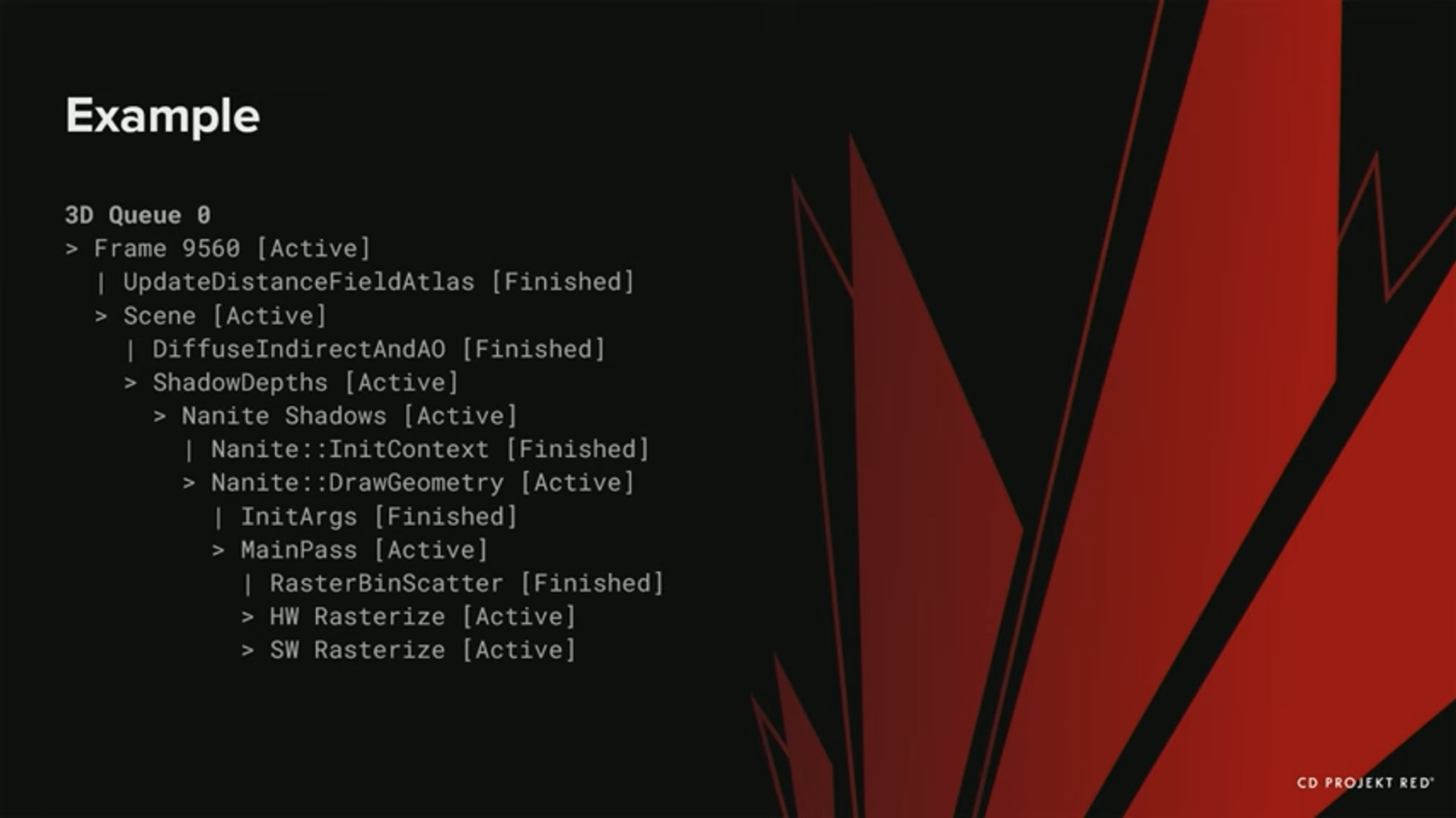
크래시가 발생하면, 계층구조와 GPU 내 모든 범위의 상태를 반환한다. 어느 브랜치가 활성화되어 있는지 알 수 있다 - 현재 실제 활성화 된 path가 두 가지임을 알수 있다. - Nanite hardware rasterize와 software rasterize path이다. 둘 다 크래시와 관련이 있을 수 있지만, 만약 이전 버전의 Breadcrumb를 사용했다면 software rasterize만 보였을 것이다.
또한 compute queue를 지원하기 때문에, 그저 그래픽스 queue만 얻는 것이 아닌 크래시 당시의 계층구조와 마커들을 볼 수 있다.
이제 커스텀 breadcrumbs의 구현으로 넘어가자.
앞서 본 것처럼, 모든 마커들은 계층 구조를 지닌다. 우리는 마커들을 RHI Push 이벤트들을 통해 GPU Profiler 에 push된 이벤트들에 기반해서 스케줄링했다. 그리고 나서, RHI Push 이벤트는 공유 버퍼(shared buffer)로의 기록을 스케쥴링한다. 아 공유 버퍼는 write buffer immediate를 사용하도록 작성되었고, 모든 마커들을 포함한다. 아래는 GPU Profiler에서 볼 수 있는 것과 같은 계층구조이다. GPU Breadcrumbs에서도 정확히 같은 내용을 확인할 수 있다.

어떻게 동작할까?
우리는 Breadcrumb 버퍼를 어플리케이션이 시작할 때 미리 할당해 두었다. 이 버퍼는 2MB 크기이고, 오픈된 heap 주소를 사용하여 생성되기 때문에 CPU 와 GPU 간에 공유될 수 있다. 보통의 경우처럼 일단 프로세스가 크래시 되면 더 이상 드라이버 GPU에 접근하지 못하도록 하더라도, 크래시 상태에서 항상 접근 가능하도록 하였다. 기본값은 2MB로 버퍼 크기를 할당한다. 우리가 Stack들을 추가하거나 제거함에 따라 pool 처럼 동작한다. 1개의 Stack은 4096 개 이상의 마커를 포함하고, scope들의 전체 계층 구조를 포함하는 데 사용된다. 이 값들은 언리얼의 통상적인 workload에 기반해서 선택된다.

configuration에 따라 더 많은, 또는 더 적은 사이즈를 할당할 수도 있다. 이것은 C++의 아래 define문을 수정하면 된다.

앞서 write buffer immediate 커맨드를 언급했는데, 우리는 이 커맨드를 Breadcrumb stack에 마커를 기록하는 데 사용하였다. 먼저 마커들의 주소를 넘겨주고, 마커의 값과 기록할 모드를 넘겨준다. 마커의 상태에도 몇 가지가 있다 - 먼저 non-starter 상태 (0) 가 있는데, 이것이 기본 상태이다. 그리고 활성화 상태 - GPU에서 작업이 시작되었음을 의미하는 상태가 있다. 그리고 완료 상태가 있다 - 이것은 작업이 GPU상에서 그 이전의 모든 작업이 완료되었음을 의미한다.
에러가 발생했을 경우에 대비한 두 가지 값이 있다.
- 첫 번째는 오버플로우 이다 : 이전에 언급했던 것처럼, 스택당 4096개의 마커까지만 지원하기 때문에 그보다 더 많을 경우, 상태는 오버플로우가 될 것이다.
- 만약 또다른 에러가 일어났다면, 상태는 invalid (유효하지 않음) 가 된다.
GPU상의 버퍼에 마커를 기록할 때 사용할 수 있는 모드는 두 가지가 있다.
- 첫 번째는 마커 in이다. 마커 in은 이전에 스케쥴링된 모든 work가 시작되었을 때만 기록된다.
- 마커 out은 이전에 스케쥴링된 모든 work가 GPU상에서 완료되었을 때만 기록된다. 따라서 모든 work가 완료될 때 까지 실제 기록은 미뤄지게 된다.
어떻게 이 모든 stack와 마커들을 추적할까?
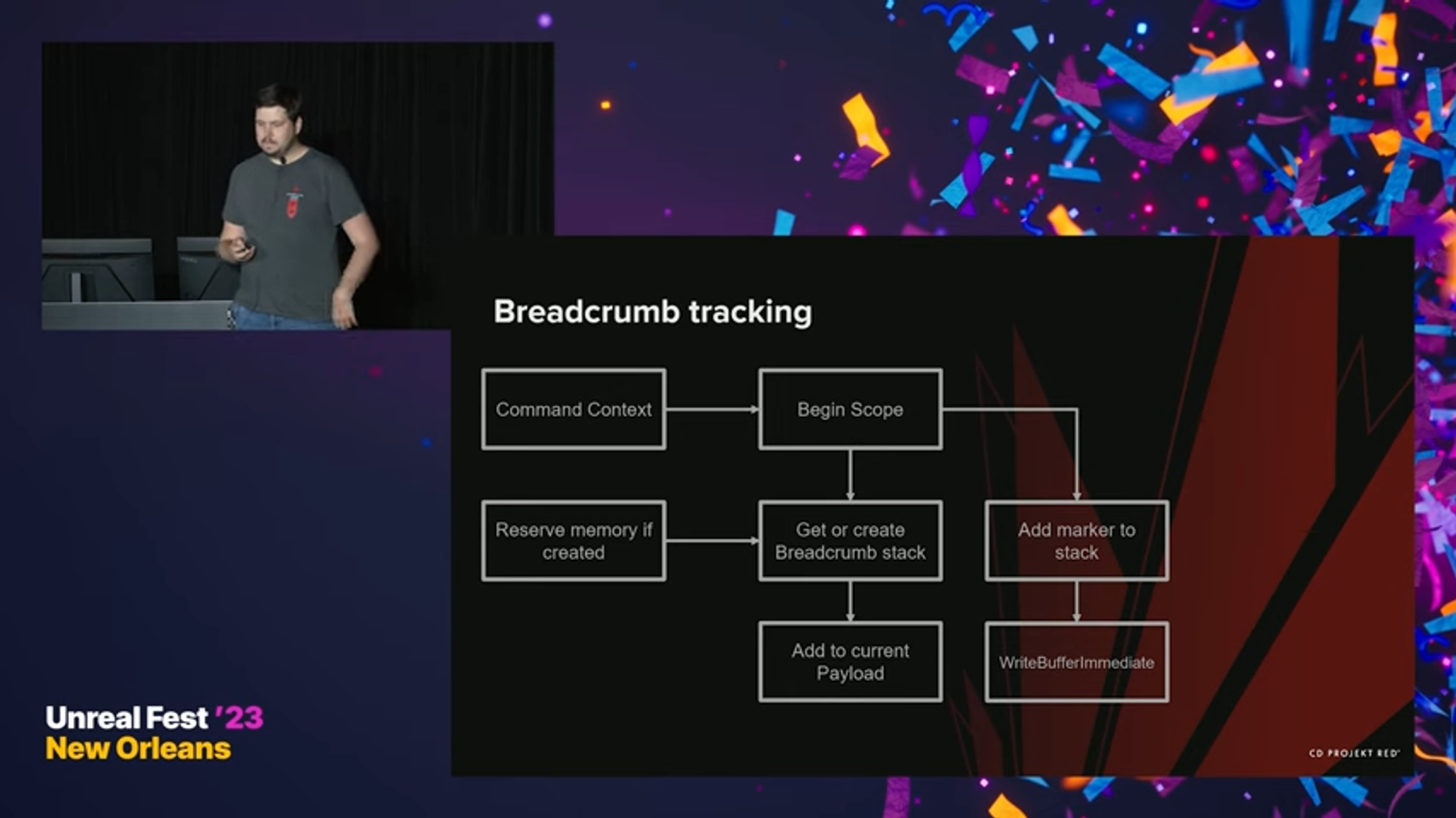
먼저, Command Context가 GPU상에서 work를 생성하는 역할을 맡는다. Command list를 만들어, GPU상에 탑재해 보낸다. Scope를 시작할 때, GPU에 마커가 시작된 상태(Started State)라는 것을 기록해야 한다. 그리고 나서, 먼저 첫 번째 Breadcrumb stack을 얻어 마커를 기록하는데 사용한다. 현재 계층구조나 GPU로의 Payload가 Breadcrumb stack을 갖고 있지 않을 수도 있다. 이 경우에는 다시 pool로 돌아가서, 마커를 기록할 메모리를 reserve 한다. 일단 stack을 얻었으면, payload에 추가한다. Breadcrumb stack을 얻었으면 이제 마커를 stack에 추가하고, 앞서 언급한 write buffer immediate 호출을 스케쥴링 할 수 있다.
각 begin scope마다, 대응되는 end scope가 있다. 그런데 이것은 훨씬 나중에 일어날 수 있다.
먼저 마커의 ‘완료’ 상태를 write buffer immediate 를 사용해 기록한다. 그리고 그 scope를 stack으로부터 pop 한다. 만약 stack이 비어있고 어디에도 참조되고 있지 않은 경우, stack을 파괴한다. 메모리가 pool로 해제되고, 다른 stack들에서 재사용될 수 있다.

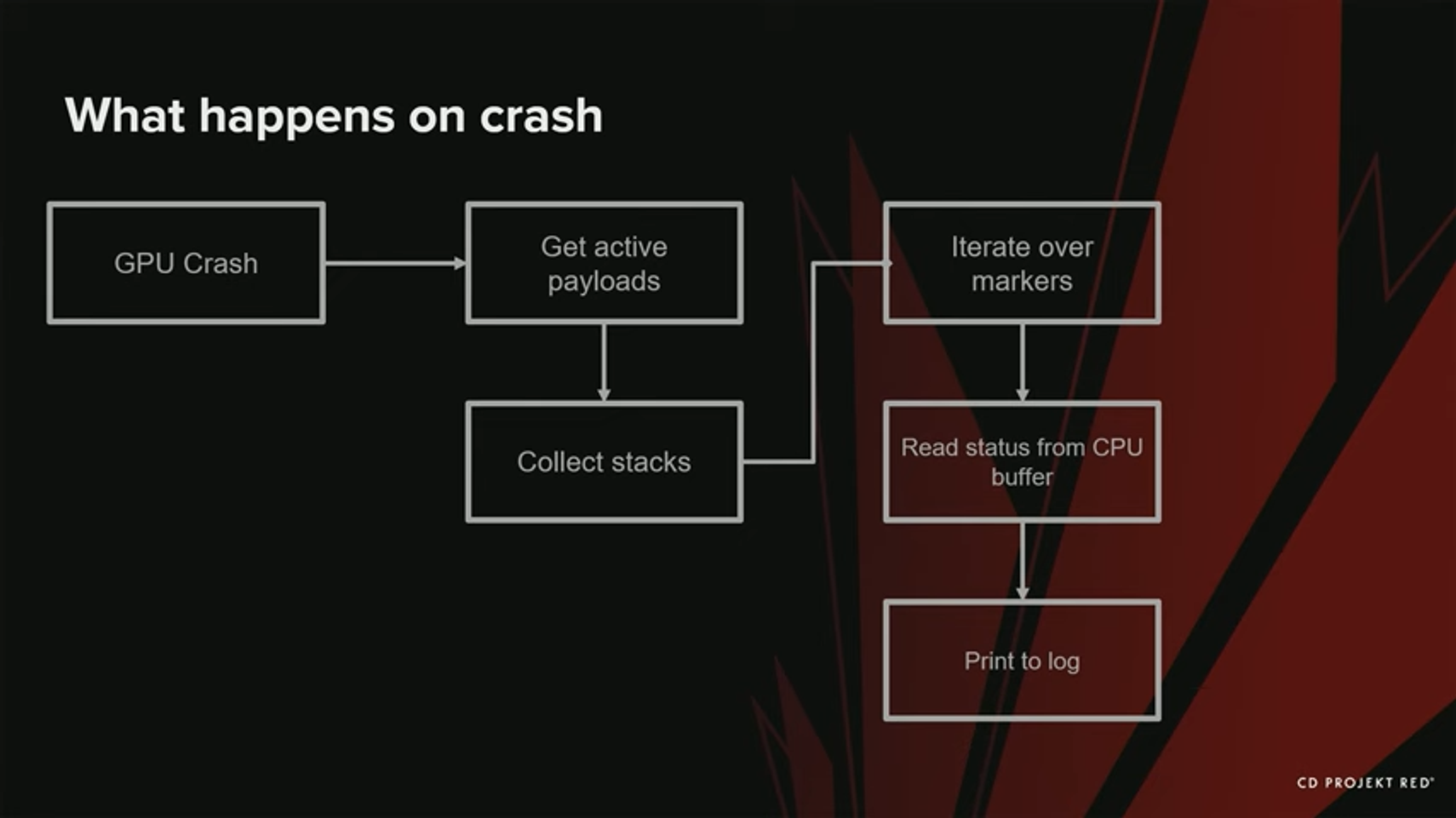
이제 stack에 마커를 기록했다. 이 데이터들을 GPU Crash가 일어났을 때, 어떻게 사용할까?
먼저, GPU상에서 활성화된 모든 payload를 얻고, 거기에 관련된 stack들을 수집한다. 그리고나서 각 고유 stack 안의 모든 마커를 순회하면서, CPU에서 여전히 접근 가능한 버퍼로부터 그 상태를 얻는다.
그 상태(status)들을 로그에 출력한다.
실제로 어떻게 동작하는지 살펴보자.
여러 개의 breadcrumb stack과 command context가 있고 각 stack과 관련된 여러 개의 payload가 있다. GPU에 payload를 제출하면, 거기에 있는 work들이 시작된다. 그러나 실제로 work가 언제 완료되었는지 알아야 한다 - 고맙게도, Unreal은 모든 payload를 추적하는 submission thread가 있어서, payload가 완료된 시점에 신호를 날려준다. Payload가 끝났을 때, GPU Work가 완료되었음을 알 수 있고, 그 특정 payload에 있는 stack의 모든 참조들을 안전하게 해제할 수 있다. 어떤 경우에는 payload들끼리 merge 될 수도 있다. 그런 경우에는, 모든 참조들을 merge 된 payload에 Breadcrumbs 태그를 병합한다.

그런데, 이 접근 방식은 잘못될 여지가 있다. 예를 들어, Breadcrumb tag가 너무 많은 경우, pool에서 16 kB 단위로 메모리를 차지할 것이다. stack 1개당 이 정도의 메모리를 차지한다. 에디터에서는 1개의 stack이 1개의 커맨드만 포함할 수도 있다. 이것은 우리가 4byte만 사용하더라도, 16 KB를 할당해야 한다는 뜻이다.
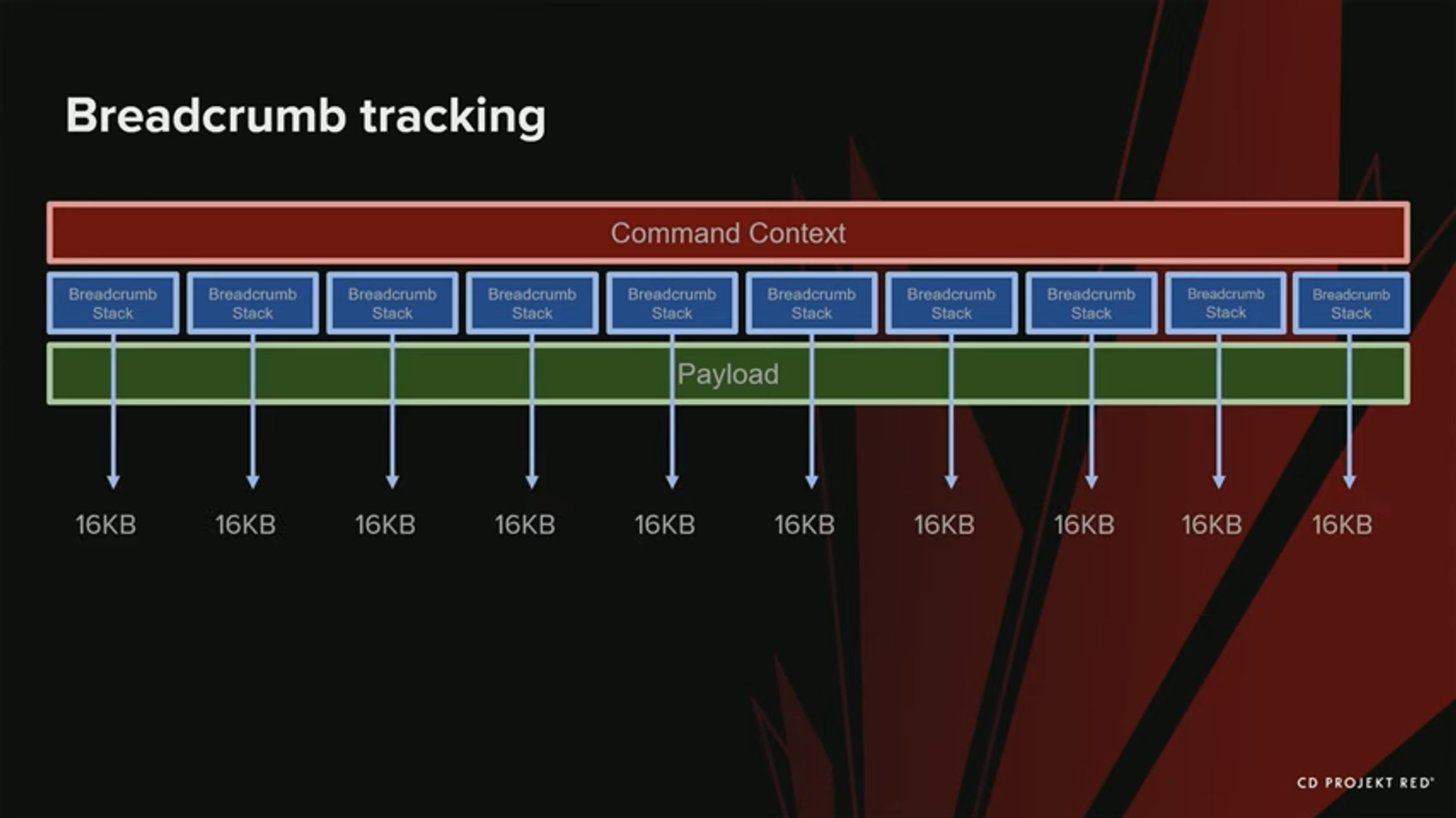
여기에서 해결책은 100개 이하의 마커를 가진 stack끼리는 merge 하는 것이었다. 하지만 이것은 그 stack들이 필요한 것보다 더 오래 유지되어야 함을 의미하기도 한다. 새로운 breadcrumb 시스템은 이전보다 훨씬 낫지만, 여전히 몇 가지 한계가 있다.
BRRS Limitations
- Editor에서는, commanlist 가 거대해질 수 있다. 이전에 말했듯이, command의 크기는 인게임이냐 에디터냐에 따라 크게 달라진다. 에디터에서, CommandList는 아주 커질 수 있다. 공간이 모자할 경우, crash된 마커의 실제 상태를 알기 어려울 수도 있다. 그렇게 된다면, 에디터 크래시를 디버그하기 위해 buffer size를 늘릴 수 있다.
- 새로운 Wwrite buffer immediate commant를 추가하는 데 CPU와 GPU에 오버해드가 생길 수 있다. 만약 scope가 많을 경우 - 예를 들어, mesh와 material draw 이벤트를 보고하는 경우, 실제 오버헤드가 발생할 것이다. DRED는 모둔 렌더 작업에 대해 enabled 되어 있기 때문에, 아주 비싸다. 만약 게임을 출시하고 실제 출시된 게임에서 breadcrumb를 사용하고 싶을 경우, 오버헤드가 눈에 띄지 않도록 scope의 갯수를 줄일 것을 추천한다. 또한 앞에서 말한 것처럼 vendor specific한 툴들이 더 정확하다 - 하드웨어에서 무슨 일이 일어나는지 더 직접적으로 접근할 수 있기 때문이다. 복잡한 크래시의 경우 DRED 또는 Breadcrumb보다 이들을 사용할 것을 더 추천한다.
Reporting Crashes
이제 GPU TDR이 일어났을 때 크래시를 어떻게 보고했는 지 살펴보자.
Brreadcrumbs를 어떻게 그룹화하고 필터링해서, 특정 GPU crash와 관련된 Jira 티켓을 생성하였는지 이야기할 것이다.
우리는 GPU crash를 발견해내는 주 도구로 Breadcrumbs를 사용하였다. 먼저, Unreal로 옮겨간 이후 GPU crash를 추적하는 아주 간단한 시스템을 가지고 있었다. 모든 GPU crash가 1개의 티켓으로 그룹회되었다. 우리는 수동으로 log를 얻어 무슨 일이 일어났는지 알아봐야 했다. 이것은 어디까지나 임시 방편이었기 때문에, 우리는 더 나은 방법이 있다는 것을 알고 있었다.

티켓은 위 이미지처럼 생겼다. CPU Call Stack 기반이었기 때문에, 대부분의 크래시에서 내용이 비슷비슷했고, 별로 유용하지 않았다. 이제 우리가 Breadcrumbs work들을 그룹화 한 접근법을 살펴보자.
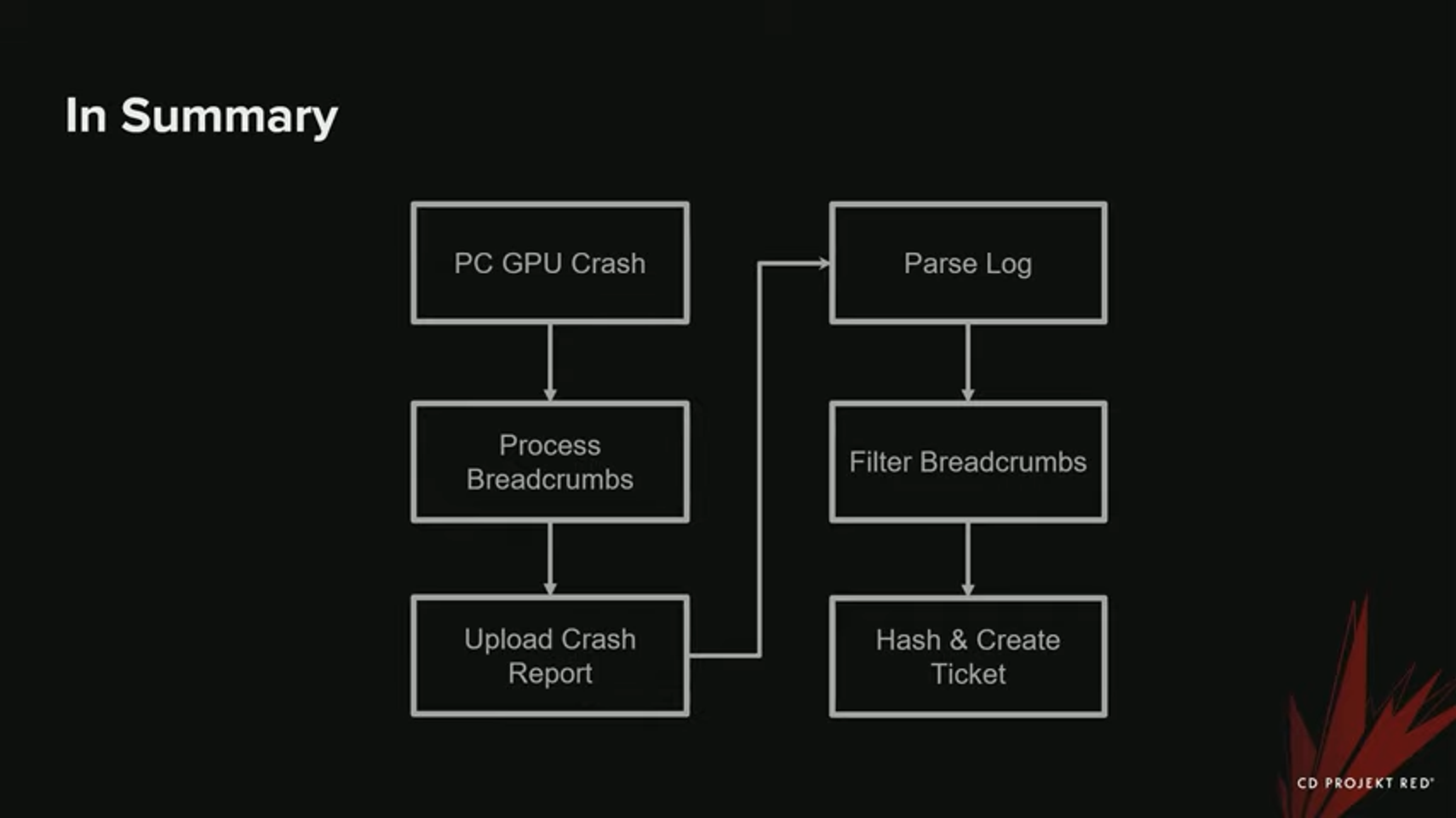
크래시가 발생하면, GPU로부터 받은 것을 기반으로 Breadcrumbs work들을 필터링하고 그룹화해서 적절한 Breadcrumbs만 선택하는 작업을 거친다. 이것을 로그로 내보내고, 크래시 리포트에 업로드한다. 그리고 백엔드에서는 스크립트로 이 log를 파싱하고, readcrumb들을 필터링하고, 패쉬(hash)하고, 티켓을 생성한다. Breadcrumbs를 해쉬하는 데 page fault 정보를 사용하지는 않았다 (얻을 수 없었기 때문에). 하지만, DRED나 NVidia Aftermath, Radeon GPU Detective를 사용한다면 이것이 가능했다.
이전 게임에서 보고하기 (Reporting in Previous Games)
앞에서 말했듯이, 이미 Breadcrumbs를 파싱하고, 활성화 상태인, 그리고 마지막으로 완료된 scope들을 기반으로 티켓을 그룹화했다. Breadcrumbs에는 보통 많은 양의 정보들이 포함되어 있기 때문에, 각 정보의 모든 부분마다 티켓을 생성하거나, 모든 부분마다 고유 해쉬를 생성하고싶지는 않았다 - 너무 많기 때문이었다. 하지만 같은 크래시를 같은 Jira에 그룹핑하고 싶었다 - 그게 더 무슨 일이 일어나고 있는지 파악하기 쉬웠고, 자주 일어나는 크래시들을 우선시하기도 쉬웠기 때문이었다.
그래서 언리얼에서도 같은 방법을 사용하였다. Breadcrumb 시스템을 포팅해 왔기 때문에, 대부분의 백엔드 코드가 동작했고, 이것을 크래시를 그룹하하는데 재사용할 수 있었다. 그래서 몇 가지 단계를 거쳐 수행했다. -
- 먼저, crash가 일어났을 때 얻은 log를 파싱한다.
- Breadcrumb를 맨 마지막에 완료되었고 활성화 된 scope를 기반으로 필터링한다.
- 필터링 된 breadcrumb로부터 모든 다이내믹 데이터를 제거한다
- 이것들이 우리의 백엔드 시스템에서 다른 티켓들을 생성해버릴 것이기 때문이다. 우리는 이것을 원치 않았다.
- 필터링 된 Breadcrumb 에 기반한 해쉬를 생성하고, 티켓을 만든다.
- 마지막으로 활성화 상태였던 scope를 타이틀로 사용한다 - 이것이 원래의 Breadcrumbs가 리포트 한 것이기도 하다. 이 내용은 어떤 때는 쓸모있지만, 어떤 경우에는 무슨 일이 일어나는 지에 대해 부정확한 정보를 제공한다. 하지만 제목은 추가적인 정보를 제공할 뿐이기 때문에, 그리 치명적인 문제는 아니다.
Filtering the BRRS
Breadcrumb를 어떻게 필터링했는지 그 예시를 아래에서 살펴보자.
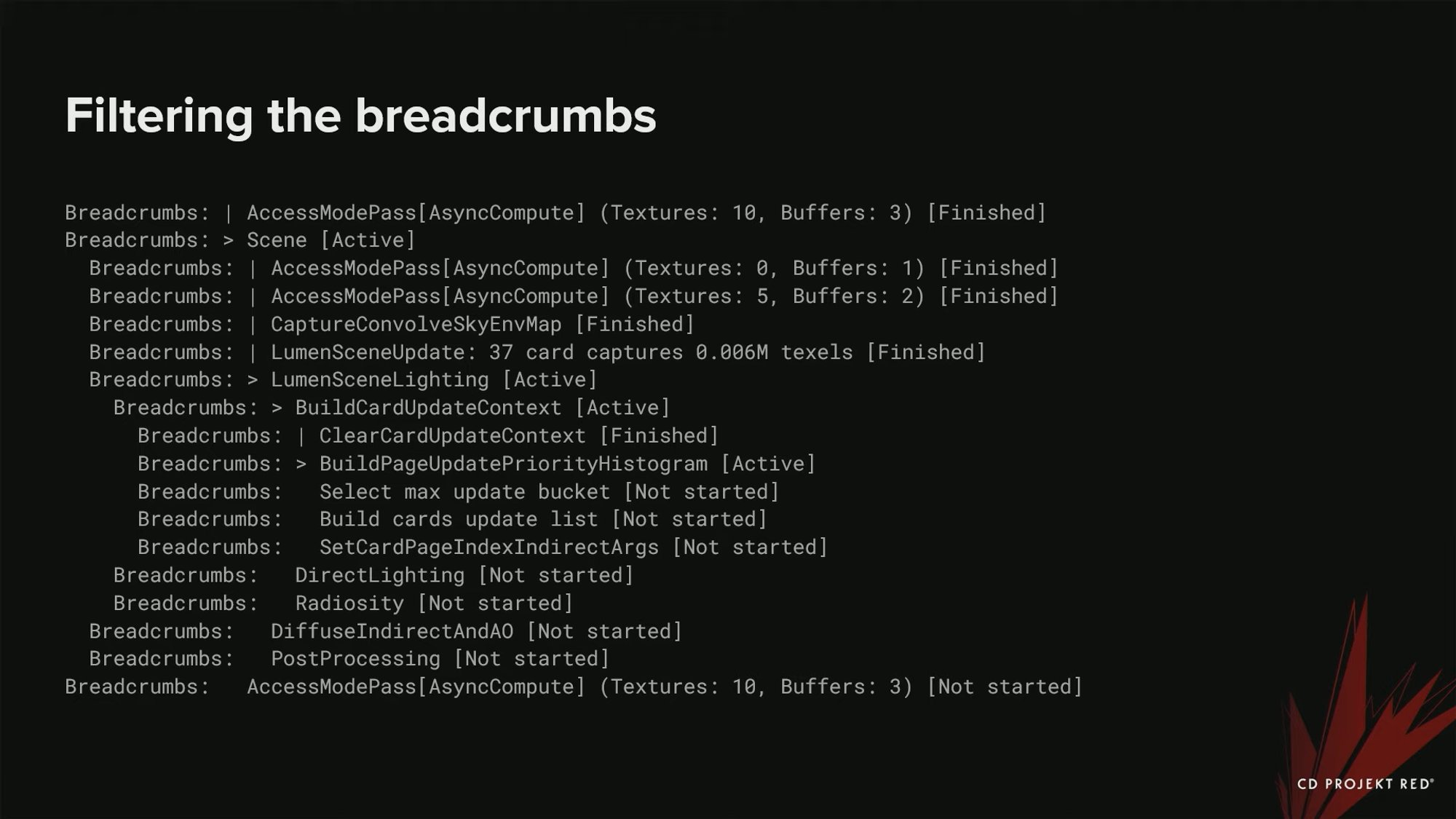
위 이미지는 TDR로부터 나온, 필터링 되기 전의 짧은 로그이다. 크래시는 Lumen쪽에서 발생한 것으로 보여진다 - 정확히는 Build page update priority histogram에서이다. 많은 정보들이 보고되었지만, 실제로 크래시가 일어난 것과 이 내용 모두가 관련있는 것은 아니다.

먼저, 맨 마지막으로 완료된 작업 이외의 모든 작업을 제거했다. 이 작업을 계층구조 안의 모든 scope에 대해 수행하였다. 컨텍스트에 대한 약간의 정보만 제공하지만, 쓸데없는 정보는 제공하지 않는다 .파란 줄은 마지막으로 완료된 scope를 나타낸다. 빨간 줄은 제거된 부분이다.
아래는 완료된 scope를 제거된 이후의 모습이다.

다음으로 시작되지 않은 scope들을 필터링 해 보자.
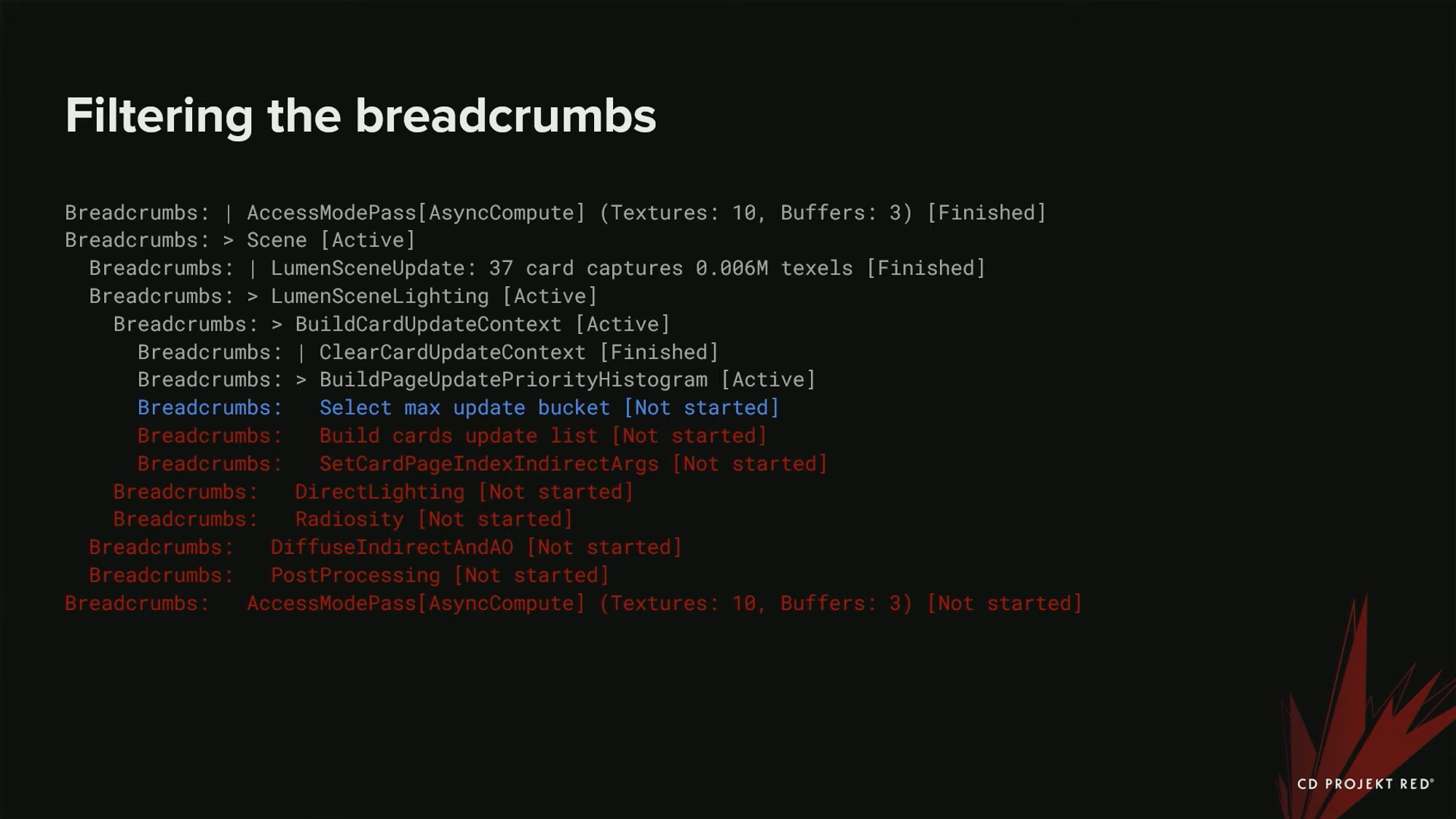
끝쪽에 시작되지 않은 scope들이 조금 있다. 파란색으로 표시된 부분이 시작되지 않은 맨 마지막 scope인데, 이 부분은 우리의 필터링 된 stack에 포함시킬 것이다 - crash가 어디에서 발생했고, GPU에 어떤 종류의 작업이 스케쥴링 되었는지 등의 컨텍스트를 포함할 수도 있기 때문이다.
시작되지 않은 작업들을 제거했으면, 아주 적은 callstack만 남은 것을 확인할 수 있다.
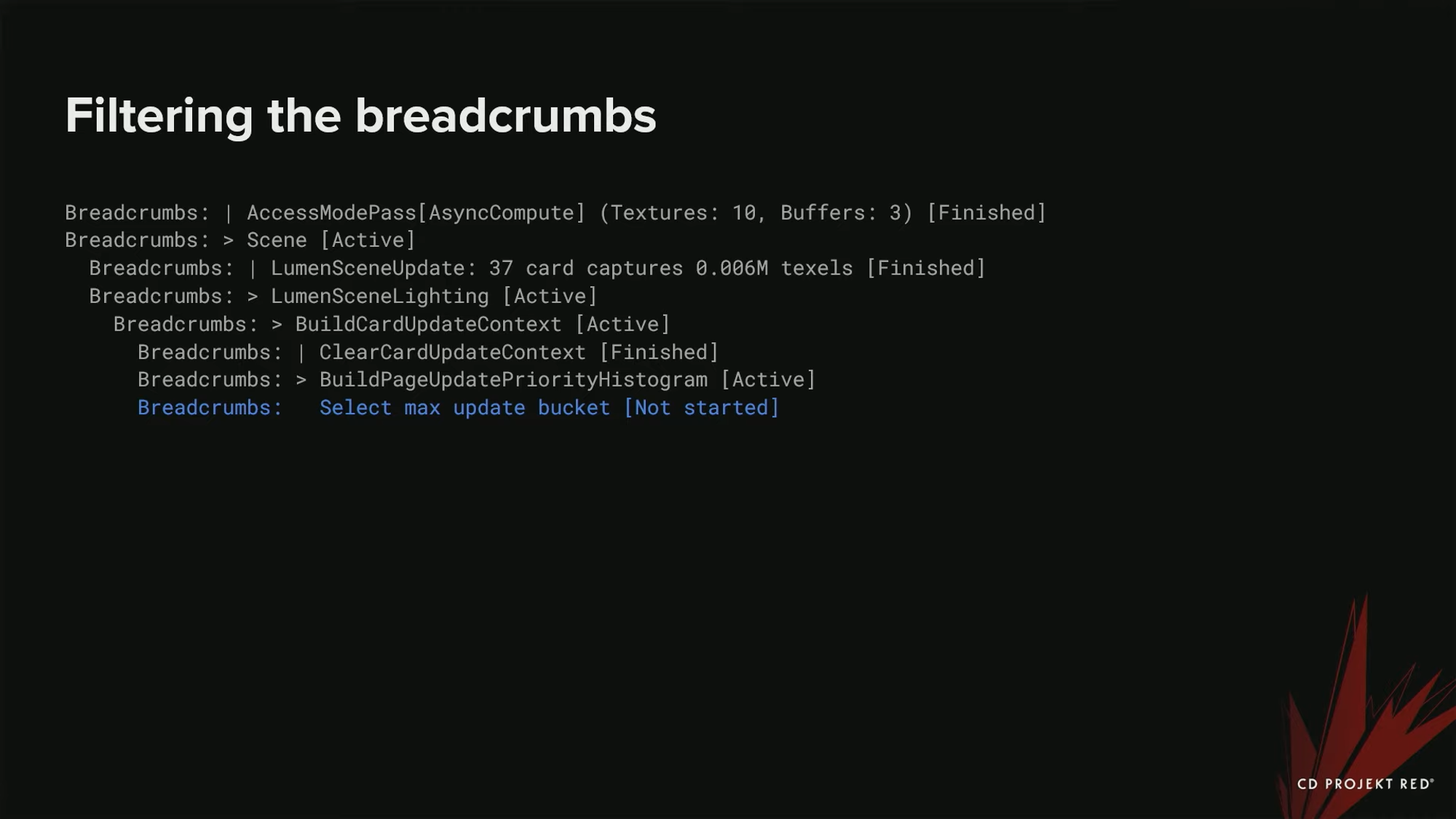
하지만 이것을 hashing에 사용할 수는 없다. 여전히 사용자가 지정한 데이터가 로그에 남아 있기 때문이다. (빨간색으로 표시된 부분)

Access mode pass와 Lumen scene update의 텍스처와 버퍼 개수, 그리고 카드 캡쳐 갯수와 사용된 텍셀의 메가바이트가 있다. 이것을 해쉬한다면 결국 아주 많은 서로 다른 티켓들이 생성될 것이다 - 매 크래시마다 이 사용자 데이터도 달라질 것이기 때문이다. 우리가 한 작업은 아주 간단했다 : 모든 숫자들을 x로 치환하였다. 아주 단순하지만, 잘 작동하였다.

이제 Breadacrumbs가 해싱할 준비가 되었다. 같은 크래시일 경우는 1개의 고유한 내용을 가진다. 이 내용을 해쉬 함수에 넣고, 해쉬가 나오면, 마지막으로 활성화 된 작업의 이름인 build page update histogram이라는 으로 티켓을 생성한다.

아래는 우리의 Jira에 있던 크래시의 예시들이다.

제목에서 보듯이, 크래시에 어디에서 일어났는 지에 대한 힌트를 제공한다 - 그림자, 스키닝, 또는 Lumen 같은 것들이다.
요약
하지만 아직도 완벽하지는 않다. 그룹화 하는데 많은 false negative들이 있다. GPU가 작동하는 방식이 불확정적이기 때문에, 어떤 작업들이 활성화 되어 실행되고 있는지 알 수 없다. 또한 이렇게 또 다른 활성화 된 작업들이 크래시를 발생시켰는지도 알 수 없다. 그렇기 때문에 같은 크래시임에도 서로 다른 티켓을 생성할 때가 있다. 패턴 매칭으로 이 부분을 개선할 수 있을 것을 것이지만, 이후의 작업이 될 것이다. 또한, 앞에서 언급한 것처럼, page fault를 지원하지 않는다. Breadcrumbs는 애석하게도 이 데이터에 접근할 수 없다. 하지만 DRED 같은 툴들은 가능하다. Page fault 정보를 로깅하거나, 크래시가 일어났을 때 범위 내에 있던 리소스들에 대한 정보도 얻고 싶을 때 데 이 툴들을 사용할 수 있을 것이다.
- crash breadcrumb는 가장 신로할 수 있는 정보는 아니다. 어떤 때는 그리 많은 정보를 돌려주지 않는다. 예를 들어, Command list all finished가 가장 많이 생성되는 티켓이다. 이것은 모든 마커가 완료된 상태라 결과가 나올 때 일어난다. - 드라이버 버그나 그외 우리가 모르는 다른 것일 수 있다. 이런 경우에는 실제로 어떤 일이 일어나는 지 더 깊이 알아보기 위해, 더 진보된 툴을 사용할 필요가 있다.
- 어떨 때는, 아주 작은 Breadcrumb를 얻을 때도 있다. 여기에는 아주 적은 양의 정보만 담겨있다. 진행중인 작업을 아주 많이 포함하고 있지만, 특히 에디터에서 무언가 많이 진행되고 있는데도, 별 정보가 없는 아주 적은 결과가 나올 때가 있다. 이런 경우에는, 역시 더 진보된 도구를 사용하거나, 콘솔에서 크래시를 재현해 본다. 이렇게 하면 더 많은 정보를 얻을 수 있다.
'GPU' 카테고리의 다른 글
| Ep 2.5 Content best practices (0) | 2024.05.26 |
|---|---|
| Ep 2.4 : Engine and API best practices (1) | 2024.04.15 |
| Ep 2.2 : Best practice principles (1) | 2024.04.08 |
| Shader Programs 최적화 (0) | 2023.09.02 |


