Arm GPU Training - Episode 2.5: Content best practices
This site uses cookies to store information on your computer. By continuing to use our site, you consent to our cookies. If you are not happy with the use of these cookies, please review our Cookie Policy to learn how they can be disabled. By disabling coo
developer.arm.com
위 영상의 내용을 요약한 것입니다.
GPU는 Data-plane 프로세서이기 때문에, 컨텐츠의 데이터 payload가 퍼포먼스에 큰 영향을 끼친다는 것을 예상할 수 있다. 이 섹션에서는 넓은 범위의 모바일 기기에서 제대로 작동하도록 효율적인 컨텐츠를 작성하는데 도움이 될 만한 몇 가지 사례들을 제시할 것이다.
지오메트리는 Mali 같은 타일 기반 렌더러에서 가장 취약점이 될 수 있는 아키텍처이다. bandwith 효율성을 약간 희생하지만, 프레그먼트 셰이딩 작업을 GPU-local 타일 메모리 안에 유지해둘 수 있기 때문이다. 따라서 지오메트리를 최대한 효율적으로 만드는 것이 아주 중요하다.
- 가장 쉬운 방법은 메시가 더 적은 수의 트라이앵글을 사용하도록 단순화하는 것이다. 이렇게 하는 것은 버텍스 매모리 bandwidth 와 셰이딩 비용을 proportional 하게 감소시킬 수 있다. 또한, 대부분의 경우에 fragment 셰이딩 효율도 증가한다. 이것은 부분적인 쿼드(partial quads)가 생성되는 갯수가 줄어들기 때문이다 - fragment shading은 2x2 픽셀로 이루어진 쿼드의 stream으로 처리되는데, 쿼드 안의 픽셀 중 삼각형의 엣지 바깥에 있는 프레그먼트들은 낭비된다. 이것은 작은 트라이앵글이 불균형하게 비용이 비싸지게 만든다. 따라서, 트라이앵글 크기를 최대한 넓게 유지해야 한다.
- 트라이앵글 갯수를 제어했다면, 다음은 버텍스 연결성을 최적화해서 버텍스 갯수를 최소화 한다. indexed draw를 사용해서, 트라이앵글 간의 버텍스 재사용을 극대회 한다. 또한, 인덱스 버퍼가 spatial하고 temporal locality 를 가졌는지 (?) 를 확인해서, reshading을 최소화 하도록 하자. 재사용이 잘 되도록 인코딩 된 메시는 1개의 버텍스를 5~6개의 트라이앵글에 걸쳐서 공유한다. 따라서, 트라이앵글 당 평균 버텍스 갯수가 1 이하인 것이 대부분의 메시에서 권장된다.
- 다음은 버텍스 인풋, 아웃풋 attribute들의 데이터 포맷과 정밀도를 체크해야 한다. 많은 컨텐츠들이 모든 인풋 attribute들에 32-bit float를 사용하는데, 이럴 필요가 거의 없고, 아주 빠르게 bandwidth를 소모할 수 있다. 테이블을 살펴보면, fp16 같은 더 작은 데이터 타입을 사용해서 절반 정도로 줄어들 수 있다는 것을 볼 수 있다.

이 표는 라이팅 계산에서 벡터를 넘겨줄 때 가장 흔하게 저지르는 효율성에 관한 실수를 보여준다.
유저는 단위벡터 3개 - 노멀, 바이노멀, 탄젠트 세 가지를 넘겨준다. 이것은 좌표계를 구성하는 세 개의 축을 의미하는데, 이 세 가지를 모두 넘겨줄 필요가 없다 - 각 벡터가 항상 90도 각도를 유지함을 알고 있기 때문이다. 이것을 알고 있으면, 3개 중 2개만으로 나머지 1개의 벡터를 셰이더 코드에서 계산해 낼 수 있고, 그 벡터에 해당하는 attribute는 생략할 수 있다. 이렇게 하는 것이 거의 항상 에너지 효율면에서 좋다. 테이블에 나와있지는 않지만, 각각의 벡터에도 비슷한 트릭을 적용해볼 수 있다. 모든 벡터가 단위벡터임을 알고 있기 때문에, X 와 Y 컴포넌트만 저장하면, Z 컴포넌트는 셰이더 코드에서 계산하면 된다. 이렇게 하면 버텍스 사이즈를 15%로 더 줄일 수 있다.
- 드로우콜 갯수를 줄이는 수단으로 애플리케이션 culling을 이미 언급하였다. 이것은 GPU에서 버텍스 카운트를 줄이는 방법으로도 유효하다. GPU는 장면에 대한 정보가 없다 - 카메라 바깥의 1만 개의 버텍스를 보내면, GPU는 이 버텍스들을 모두 처리할 것이고, 버텍스 위치를 cull 되기 전에 결정한다. 이렇게 되면 상당한 양의 과도한 처리가 추가된다.. 애플리케이션 단에 있는, 장면에 관한 고수준의 정보를 사용해서 소프트웨어 쪽에서 최대한 culling을 수행햐아 한다. 여기에는 카메라 뷰 바깥에 있는 것들을 culling 하는 frustum 테스팅과, frustum 안쪽에 있지만 벽이나 바닥, 천장으로 가려지는 것들을 culling 하는 portal culling 도 포함된다.
- 마지막으로 tessellation 셰이더와 geometry 셰이더를 피할 것. 이 두 가지는 늘어나는 지오메트리 복잡도가 메인 메모리에 영향을 주지 않고 GPU 안에 머무는 immediate mode GPU 아키텍처를 위해 고안된 기술들이다. 만약 지오메트리 복잡도가 증가한 채로 GPU 안쪽에 머무를 경우, 메인 메모리를 증가시키지 않는다. Tile-based GPU의 경우, 증가한 지오메트리 복잡도가 fragment shading에 앞서 일부 메인 메모리로 다시 읽어들여지기 때문에, 이 두 가지 테크닉은 알맞지 않다.
- 카메라와 오브젝트의 위치가 비교적 고정되지 않은 컨텐츠의 경우, 각 오브젝트들은 LOD, 즉 여러 단계의 디테일 단계가 함께 제공되어야 한다. 게임 엔진은 카메라에서 오브젝트가 멀어질수록 더 단순한 메시를 선택한다. 겨우 10 px 높이의 모델에 몇천 개의 트라이앵글을 사용할 필요는 없다. 여기에서 LOD를 사용하는 주된 목적은 오브젝트의 실루엣 엣지를 유지하는 것이어야 한다. 다른 지오메트리 디테일은 텍스처나 라이팅 등으로 채워질 수 있다. LOD를 제작할 때는, LOD0에서 인덱스를 뜨문뜨문 샘플링하는 방식을 지양해아 한다. Mali GPU들은 버텍스들을 4개의 연속된 묶음으로 셰이딩한다. 따라서, 버텍스 4개마다 1개씩 샘플링해서 LOD를 만드는 것은 곧 모든 메시를 셰이딩하는것과 같기 때문에, 아무 이득도 없다. 대신, 필요한 버텍스만 타이트하게 패킹해서 LOD를 제작하자. 이렇게 하면 메모리상의 버퍼 크기가 더 커지지만, 사용되는 LOD에만 접근하기 때문에 실제 프레임 당 bandwidth는 더 적어진다.
Pseudo geometry
- 초심자들이 흔히 저지르는 실수는 인게임에서 아주 섬세한 디테일의 모델링을 하려고 하는 것이다. 이렇게 하면 아주 밀도 있는 트라이앵글을 사용해야 하기 때문에 아주 비싸고, 모서리에 트라이앵글이 빽빽하기 때문에 aliasing 아티팩트가 생길 수 있다. 디테일한 메시를 사용하려면, 실로엣의 엣지를 유지할 정도로의 적절한 수준의 트라이앵글을 사용하고, 오브젝트 표면의 디테일은 노멀 맵 같은 텍스처 베이스의 테크닉들을 사용할 것을 권한다. 이런 것을 가상 지오메트리라고 하는데, LOD 와 같은 기술들과 함께 사용되면, 메시의 복잡도를 상당히 줄일 수 있을 뿐만 아니라, 많은 경우에서 실제로 시각적으로도 더 향상되는데, 텍스처들은 다운스케일 되었을 때 아주 밀도 있는 메시보다 더 잘 동작하기 때문이다.

첫 강의에서, 과도한 처리량을 최소화하기 위해 수행되는 동작들의 순서를 재구성하는 지오메트리 처리 파이프라인에 대해 소개하였다. Bifrost 이후의 모든 Mali GPU 제품군은 최적화된 index-driven 버텍스 셰이딩 파이프라인을 사용한다. 이것은 참조하는 모든 버텍스의 위치를 계산해서, 프리미티브 조립과 컬링 스테이지를 수행한다. 그리고 나서 non-position 버텍스 셰이더 결과물을 나머지 버텍스들로부터 연산한다. 잘 작동하는 어플리케이션에서도, 거의 절반 가까운 버텍스가 back-facing 트라이앵글에만 속해 있기 때문에 컬링된다. 따라서,position shading 스테이지가 position을 계산할 때 필요한 데이터만 건드리고, 그 이외 사용되지 않는 무관한 데이터는 가져오지 않는다것은 아주 중요하다. 이러한 scheme에서 최선의 퍼포먼스와 에너지 효율을 끌어내려면, 어플리케이션에서 input buffer가 적절하게 패킹되어야 한다.

위 그림을은 이전 단계에서 최적화 된 버텍스이다. input attributes 에 posiition shader에서 필요한 단일 공간을 포함하는 것이 보인다. (첫번째 줄) 나머지 네 개 데이터는 fragment 셰이더에 전달할 non-position 결과물만 연산한다.
흔힌 메모리 레이아웃 형태 중 하나는 구조체 배열 (array-of-struvture, AoS) 이다. - 각 버텍스들을 메모리상의 연속적인 공간에 저장한다.

위 예시에서는 각 버텍스가 32 byte 크기이다. 그리고 DDR로부터의 GPU line fetch는 64 byte이다.
따라서, 1개의 DDR fetch는 2개의 버텍스 전체를 가져올 수 있다. 이 scheme의 단점은 position data가 non-position data와 함께 배열되어 있다는 것이다. position shader 단계에서의 position을 fetch하면, non-position 데이터 또한 모두 fetch 하게 된다 - 같은 캐시 라인에 있기 때문이다. 그리고, 절반의 확률로 non-position 데이터는 사용되지 않을 것이다. 이 모델에서 데이터 fetch의 대략 30%는 불필요하다.

더 나은 구조는, 그림과 같이 두 개의 분리된 array-of-structure 배열로 버텍스를 저장하는 것이다.
첫 번째 배열은 position 계산을 위해 배열된 데이터들을 포함한다. 두 번째 배열은 나머지 버텍스 셰이더에 필요한 정보를 담고 있다. 이제 position shader는 position 관련된 필요한 데이터들만 fetch 할 것이고, 어플리케이션은 IDVS Scheme 덕분에 bandwidth를 절약할 수 있게 된다.
Geometry in the UI
- 유저 인터페이스 대부분은 geometry complexity 면에서 비교적 단순하다. 하지만 개발자들이 주의해야 할 몇 가지 영역들이 있다.
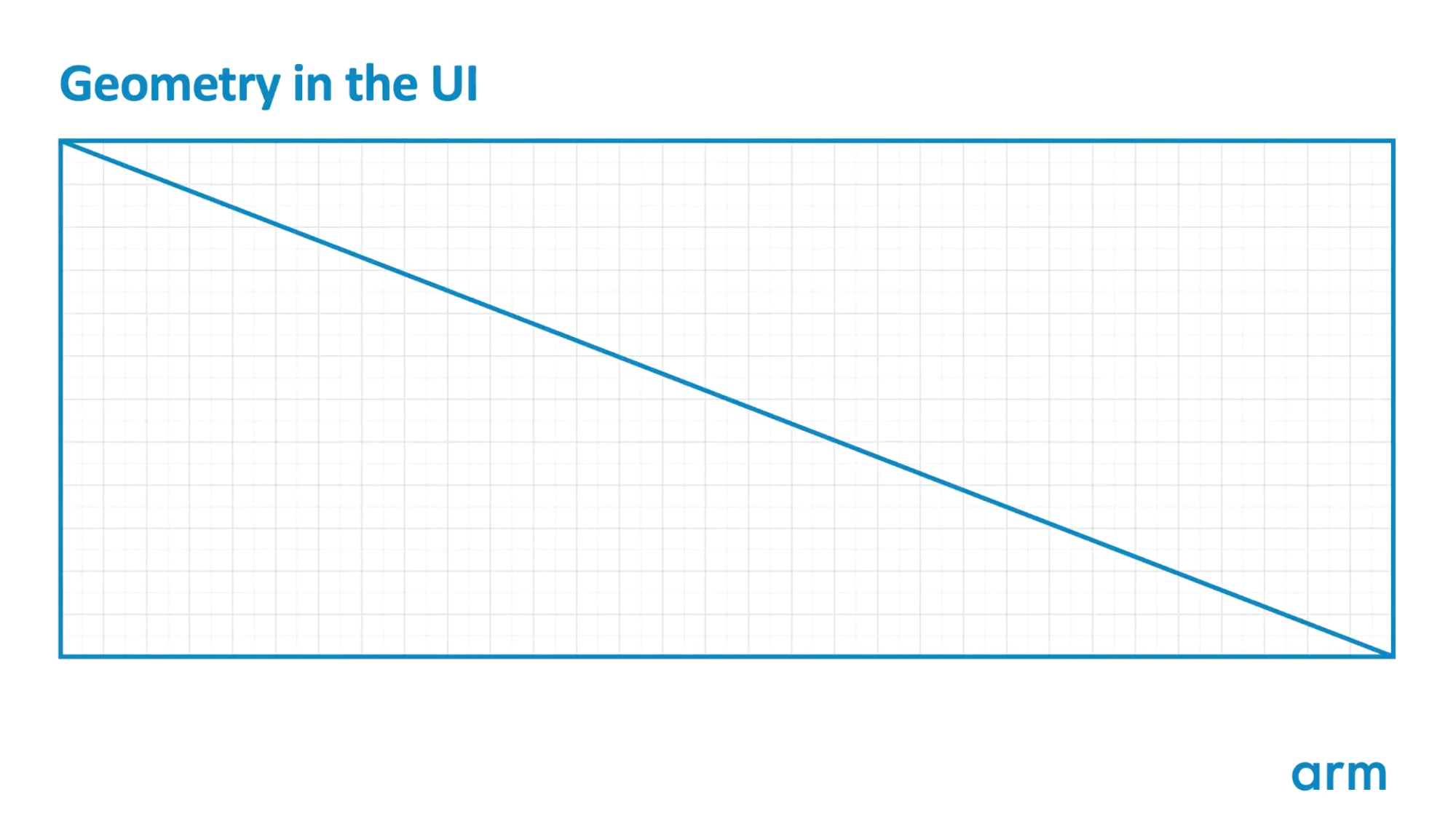
이 그림은 사각형을 렌더링하는 보편적인 방식을 나타낸다. 셰잎을 나타내기 위해 두 개의 트라이앵글을 사용하고 있다. 이것은 실용적이지만, fragment 셰이딩에 1%의 오버헤드를 준다 - fragment shading 를 하는 도중 2x2 픽셀 쿼드를 사용하기 때문이다. 주황색으로 표시된 부분은 두 번 셰이딩 연산 될 것이다 - 한 번은 왼쪽 아래 삼각형, 한 번은 오른쪽 위 삼각형에서..
쿼드가 두 삼각형 모두에 덮여 있기 때문이다.
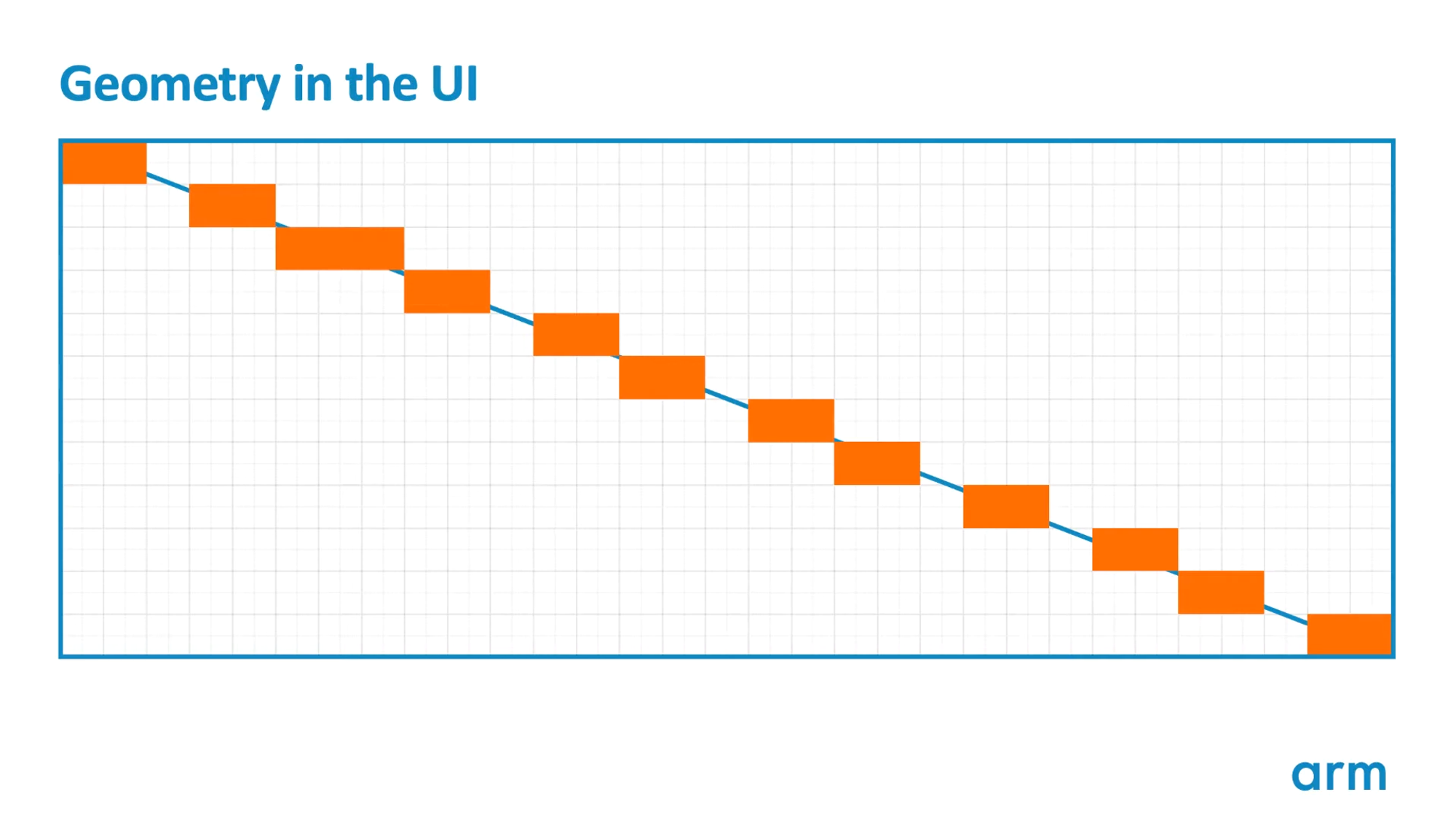
큰 사각형을 그릴 때 더 좋은 방법은, 실제 필요한 가로, 세로 크기보다 두 배 더 큰 삼각형을 그리고, scissor box 또는 viewport 를 사용해서 실제 필요한 부분만 렌더링 되도록 하는 것이다.

이렇게 하면, 같은 스크린 커버리지를 가지면서도, 대각선의 seam은 없앨 수 있다.
실제로는, 1개의 대각선 seam이 있다고 해서 큰 문제가 되지는 않는다 - 나머지 다른 쿼드들에 비해서 적은 오버헤드를 주기 때문이기도 하고, 또 다행히 UI는 그리 비싸지 않은 셰이더 프로그램을 사용하기 때문이다. 하지만, 둥근 모서리나 곡선형 모양을 렌더링할 때처럼 좀 더 조밀한 트라이앵글을 사용하는 컨텐츠들도 있다.
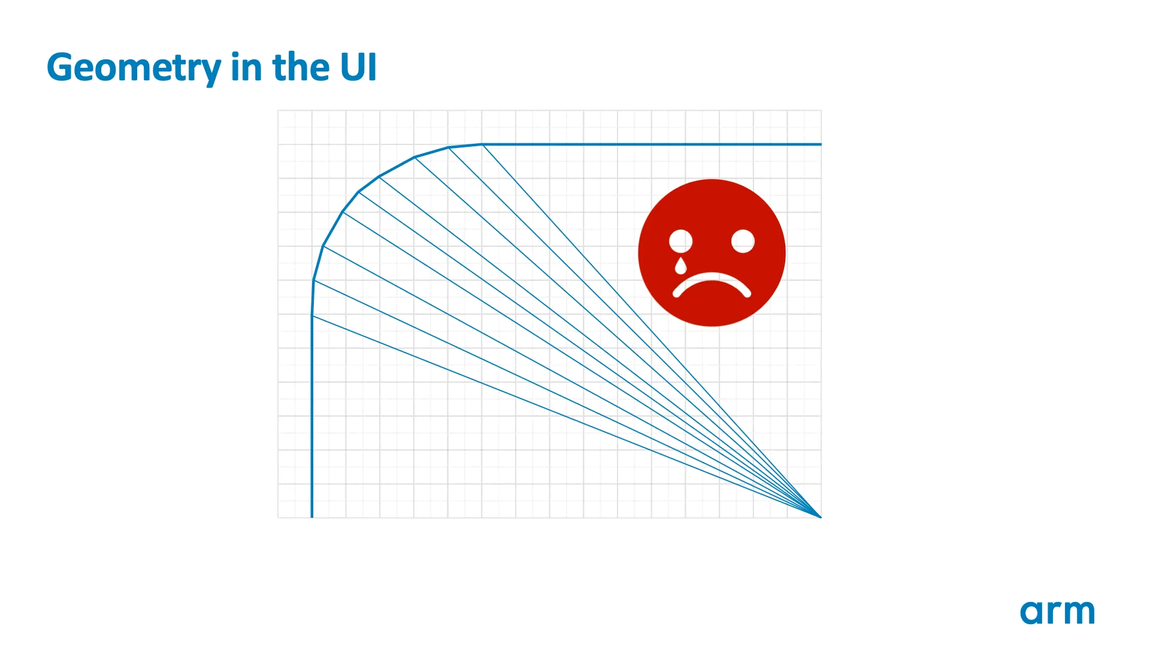
위와 같이 중심점으로부터 펼쳐져 나온 삼각형들로 둥근 모서리를 표현할 때, 길고 얇은 삼각형들이 만들어진다. 여기에서 부분적으로 덮여지는 쿼드들이 많이 생성되기 때문에 오버헤드가 발생한다. 이 영역이 많은 픽셀들을 차지하게 되면, 오버헤드가 빠르게 증가할 수 있다.
더 나은 해결법은 셰입을 recursive하게 쪼개서 둥근 코너를 표현하는 것이다.

이렇게 해도 여전히 코너에 두 개의 대각선이 생기지만, 점점 더 작은 크기의 트라이앵글로 쪼개지기 때문에, 대각선 모서리의 길이도 점점 줄어들게 된다.이렇게 되면 area-to-edge ratio (영역 당 모서리 비율) 이 극대화되고, 부분적으로 덮이는 쿼드 갯수가 최소화된다. 위에서 본 좋지 않은 예시와 이번 예시의 버텍스 갯수는 동일하다는 점에 주목하자. 다른 점은 버텍스 순서와 프리미티브 조립 방식이다.
Texturing essentials
텍스처에서는 두 가지 중대한 권장사항이 있다.

- 첫째로, 오프라인 텍스처 전부 텍스처 압축을 사용하고 있는지, 그리고 3d 오브젝트들에서 mipmap을 사용하고 있는지를 확인하자. 두 가지 모두 메모리 점유량과 런타임 시 메모리 bandwidth를 크게 줄일 수 있다.
- OpenGL ES2 하드웨어를 위해 고안된 낡은 테크닉을 사용해서 출시하는 경우가 여전히 종종 있다. 오래된 하드웨어들은 보통 ETC1 텍스처 포맷만 지원하는데, 이것은 RGB 포맷이다. RGBA 를 구현하기 위해서는 너비가 두 배인 텍스처로부터 두 개의 서로 다른 텍스처 룩업을 해야 한다. 샘플링 1번은 RGB 값을 fetch 해오고, 나머지 1번은 알파값을 얻어온다. 이것은 컴포넌트 4개를 지원하는 ASTC 또는 ETC2+EAC 같은 포맷의 텍스처 1장을 샘플링하는 것 보다 훨씬 비싸다. 따라서, 좋은 대체재가 있기 때문에, 현재 하드웨어에서는 ETC1 포맷은 피하는 것이 좋다.

- 압축된 텍스처를 사용할 때는, 새로운 타이틀을 출시할 때 ASTC를 기본값으로 사용하고, ASTC를 지원하지 않을 경우 fallback으로 ETC2 것을 권장한다. 2012년부터 ASTC 가 기기에 탑재되어 출시되고 있고, OpenGL ES3.2 에서는 필수가 되었다. 따라서, 2D LDR 프로필은 이제 모바일 기기에서 모두 지원된다. 그리고 많은 기기에서 2D HDR 프로파일도 지원한다. ASTC는 ETC2+EAC에 비해서 두 가지 큰 장점을 갖고 있다. 첫째로, ASTC는 훨씬 유연한 압축 포맷이다 - 같은 bitrate 에서 훨씬 더 나은 이미지 품질을 얻을 수 있다. 두 번째로, 다양한 bitrate 선택지를 제공해서, 사용자들이 텍스처 메모리 사용량과 bandwidth 소모를 아주 세밀하게 튜닝할 수 있도록 해 준다.반면, 미리 구워진 라이트맵들은 보통 low-frequency 텍스처들이기 때문에, 8x8 block 을 사용해 2bpp로 압축할 수 있다.기본적으로 sRGB Profile을 사용할 경우는 32bit이고, 나머지 경우는 64bit 이다.
셰이더 코어의 텍스처 캐시를 최대한으로 활용하려면, decode mode 확장을 사용할 것을 권장한다. 이렇게 하면 압축 해제된 텍스처들의 정밀도가 32-bits per pixel로 감소한다.
bitrate를 선택하는 기준은 압축될 리소스에 따라 다르다. 3d 오브젝트의 albedo 또는 diffuse 텍스처는 6x6 block을 추천한다- 이것은 픽셀당 3.56 bit를 저장한다. 이것은 ETC2 보다 10% 더 적지만, 여전히 전반적으로 더 나은 이미지 품질을 준다. 보통의 경우, 2D UI 오버레이나 3D 노멀 맵에 사용되는 텍스처들은 3D 오브젝트 albedo 텍스처들보다 더 높은 품질이 필요하다. 따라서, 이 경우들에는 5x5 block 를 사용해 5.12 bpp 로 bitrate를 상향할 것을 권장한다. - 텍스처 샘플링에 드는 비용은, 사용된 텍스처 필터링 모드의 알고리즘 비용에 따라 다르다. 캐싱이 완벽하게 되더라도, 텍스처 필터를 바꾸는 것은 샘플링에서 더 많은 cycle이 수행되고, 메모리 bandwidth도 더 많이 소모한다.
가장 기본적으로 사용되는 필터는 bilinear filter - OpenGL ES 의 GL_LINEAR_MIP_NEAREST 필터이다. 각 샘플은 1개의 밉맵 단계에서 2x2 패턴으로 4개의 텍셀을 얻어내서, 샘플링 된 지점으로부터의 거리에 따라 네 값을 섞는다. 이것이 Mali GPU에서 지원되는 가장 빠른 필터이다 - 가장 빠른 처리와 가장 적은 텍스처 bandwidth를 사용한다.

그 다음 필터는 trilinear filter, 또는 GL_LINEAR_MIP_LINEAR 필터이다. 각 샘플이 두 개의 blilnear 샘플을 두 개의 인접한 mipmap으로부터 만들어내고, 그 두 가지를 섞는다. 이것은 기본 bilinear 필터의 절반 속도로 수행되고, 같은 샘플 대비 5배 bandwidth를 필요로 한다. (더 디테일한 mipmap 으로부터 데이터를 얻어오기 때문이다)

최신 하드웨어에서는 anisotropic filtering도 지원하는데, 픽셀이 각 방향으로 텍스처를 얼마나 차지하고 있는지를 추정하기 위해 bilinear 또는 trilinear 샘플을 여러 번 수행한다. 이 필터는 비스듬한 각도에서도 디테일을 보존하는 환상적인 필터이지만, 아주 비쌀 수 있다. 4x MAX_ANISOTROPY 의 trilinear 필터는, 샘플 1번이 8 cycle 필터링을 필요로 한다. 또, 어떤 샘플이 mip 단계 3에서 0으로 이동할 경우, 64베 이상의 bandwidth 가 필요할 수도 있다. 아주 좋아 보이는 필터지만, 주의해서 사용해야 한다.

이 이미지는 여러 필터 타입을 비용 순으로 정렬한 것이다. 여기서 주목할 것은 anisotropic 필터도 주의해서 잘 사용한다면, 감당할 만한 퍼포먼스 오버헤드를 가진다는 것이다. bilinear 필터 tap과 3x MAX_ANISOTROPY로 anisotropic 필터를 사용한다면, 최대 2개의 bilinear 샘플을 소모하지만, 많은 경우에서 1개만 소모한다. 따라서, 평균적으로 , (항상 2 컴포넌트 샘플을 필요로 하는)전통적인 trilinear 필터보다 더 저렴하다. 이미지 퀄리티와 퍼포먼스 향상을 모두 제공하기 때문에 tirlinear보다도 권장될 수 있다.
또 다른 것은 MAX_ANISOTROPY 값이 2의 승수가 아니어도 된다는 것이다. 만약 2가 적절한 품질을 제공하지 못한다면, 4를 테스트하기 전에 3을 먼저 시도해 봐도 된다.
Video surface essentials
영상 디코더는 대부분 메머리에 YUV 포맷으로 텍스처를 생성한다 - RGB 보다 더 bandwidth 면에서 효율적이기 때문이다. 메모리상에서 RGB 포맷으로 변환할 필요가 없게 하기 위해, Mali GPU의 셰이더 코어는 YUV surface를 직접 읽어서 RGB 데이터로 변환할 수 있다.
(이 부분은 생략)
Blended Overdraw
모바일 기기에서의 2D 렌더링은 3D 게임의 파티클 시스템, UI 등 모든 것들에서 사용되고 있다.
2D 컨텐츠에서 주로 볼 수 있는 퍼포먼스 문제는 blended oveddraw (혼합 오버드로우) 이다 - 프레임 한 장에서 여러 개의 층으로 구성된 fragment들이 모든 픽셀을 덮고 있는 것이다. 만약 이 fragment들이 불투명(opaque) 하지 않다면, 모든 층들이 각각 셰이딩 된 다음, 앞에 있는 레이어들과 블렌딩 돼야 한다. 이렇게 되면, 보급형 기기에서는 GPU 부하를 빠르게 일으킬 수 있다 - 모바일 기기의 화면 해상도가 높아서 그렇다 (각각의 레이어 내용은 단순하더라도)

위 이미지는 횡스크롤 게임에서 각각 다른 속도로 스크롤링 되어, 깊이가 있는 것처럼 보이게 하는 배경 예시이다.

레이어 간 자연스러운 트렌지션을 위해 알파 투명도를 사용하는데, 뒤에서부터 앞으로 모든 레이어들을 렌더링 해서, 의도한 대로 블렌딩 되도록 해야 한다.

레이어 1개에서 투명한 영역을 핑크색으로 표시해 보면, 레이어 전체를 그리는 것이 아주 낭비라는 것을 알 수 있다.

버텍스를 조금 더 사용해서 각 레이어에서 필요한 부분만 따내도록 할 수 있다. 이렇게 하면 투명한 부분들이 완전히 버려진다. 버텍스를 추가하는 것은 비용이 비싸기 때문에, 최소한의 갯수만 추가하도록 하였다. 오려낸 부분이 아주 정확하지 않아도 된다.

오려낸 각 레이어가 어떻게 동작하는지 위 이미지를 통해 살펴보면, 여전히 화면 가운데 수평선과 땅 주위에 오버드로우가 있음을 볼 수 있다. 이 예시에서는 최대 6x, 최소 4x의 오버드로우가 있다. 대부분의 레이어를 불투명하게 처리했는데도, 여전히 필요 이상으로 비싸다 - 이것보다 더 좋아질 수 있다.

다시 레이어들 중 하나로 돌아가 보자. 각각의 빌딩과 투명한 창의 경계면이 부드러운 엣지로 처리되길 원하기 때문에, 블렌딩을 켠 상태로 레이어를 그려야 한다. 그러나 실제로는 레이어 대부분 영역이 불투명 - Opacity 1.0 의 값을 가진다.
오버드로우를 없앨 수 있는 GPU 하드웨어 기능인 Early Z Testing이나 Hidden Surface Removal 를 사용하려면, 블렌딩 없이 레이어를 그래야 한다. 따라서 메시를 두 개의 영역으로 나눌 것이다.

첫 번째 파트는, 레이어의 불투명한 영역만 단순히 그린다. 다시 말하자면, 완벽할 필요는 없다. 이 단계를 위해 버텍스 몇 개를 더 추가할 것이다. 이 경우에는 70개의 버텍스를 추가해 컷아웃을 구현하였다. 레이어의 이 부분은 블렌딩이 꺼진 상태로 그려질 수 있다 - 여기에는 투명한 fragment가 없기 때문이다.
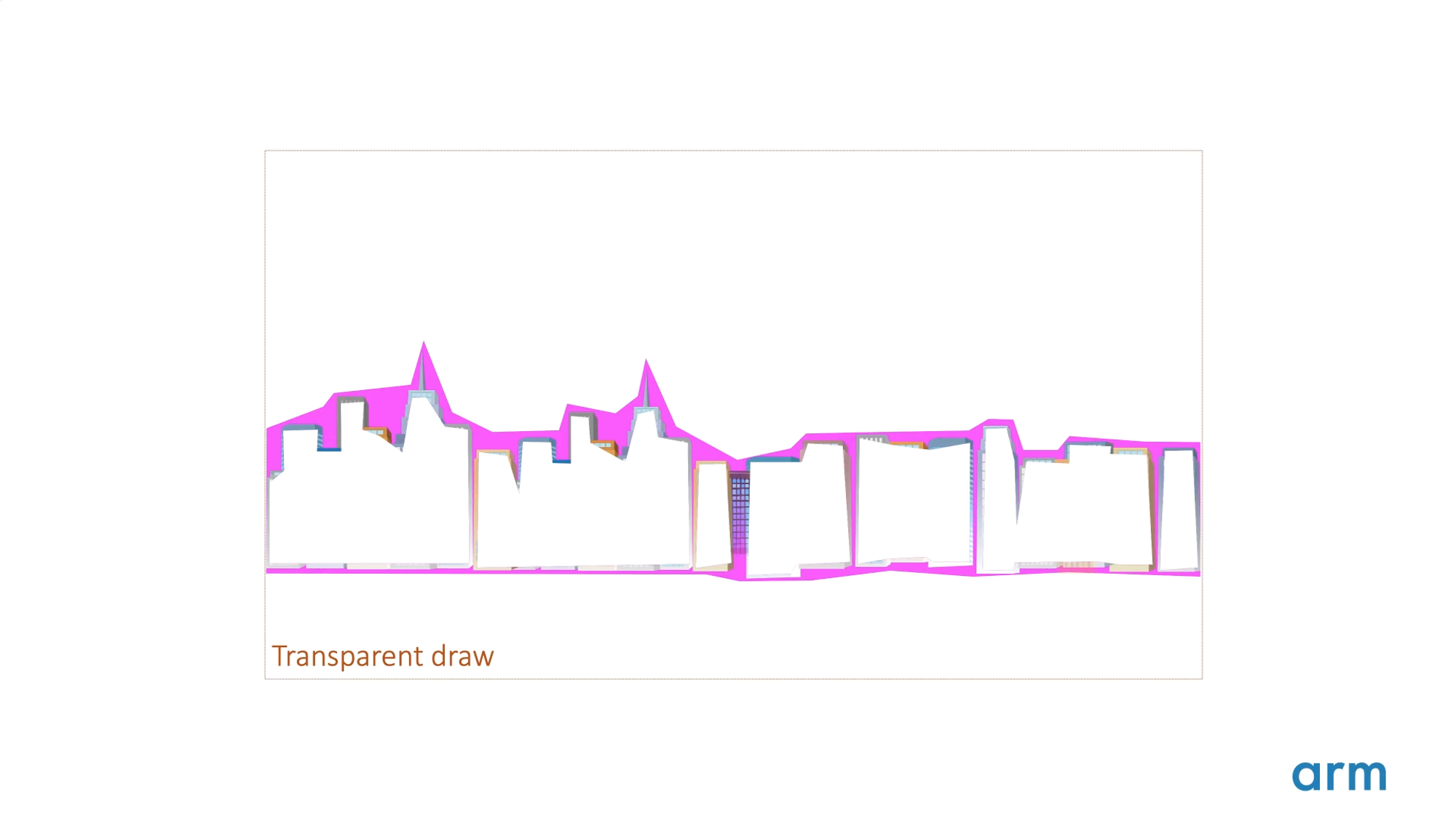
나머지 영역에는 앞서 오려낸 불투명한 영역을 제외한 나머지 영역이 있다. 이 부분들은 원하는 시각적인 효과를 얻기 위해 블렌딩이 켜진 상태로 그려져야 한다.

그림에서 보듯이, 레이어를 그리려면 두 가지 드로우를 병합해야 한다. 초록색의 불투명한 영역과, 주황색의 투명한 영역이다.
이 상태에서, 컷아웃을 더 타이트하게 할 수 있다. 투명한 영역의 픽셀 갯수를 줄일 수 있겠으나, 여기서부터는 버텍스 및 트라이앵글 갯수와 투명한 픽셀 간의 트레이드오프가 발생한다. 여기에서의 목적은 80:20 고정 비율을 적용해, 추가되는 복잡도를 최소화 하는 것이다.

이제 분리된 레이어들로 장면을 렌더링한다. 이것을 렌더링하는 최선의 방법은, 각 레이어를 장면 내의 Z Plane에 적용해서 3D 장면처럼 다루는 것이다. 3D 장면을 렌더링 할 때처럼, 각 불투명한 부분들을 앞에서 뒤 순서로 렌더링한다. Depth Buffer의 내용을 채우기 위해 Depth testing을 사용하고, 다시 이 depth test를 사용해서 카메라에서 더 가까운 불투명 픽셀에 의해 가려지는 부분을 cull 한다. 이러한 접근방식은 culling과 오버드로우 최소화라는 점에서 가장 최적의 동작을 보장한다. 하지만, 가상의 3D 장면처럼 동작하게끔 하게 위해 엔진 쪽에서 지원이 필요할 수 있다.
대부분의 경우에서 잘 동작하는 방법은, 오버드로우를 cull 하도록 hidden surface removal 에 의존하는 것이다. 이 경우에서는 렌더러가 투명한, 그리고 불투명한 부분 모두 레이어 하나하나 뒤에서 앞 순서대로 그린다. 이렇게 하면 Early ZS 를 사용할 수 없게 되지만, hidden surface removal이 대부분의 오버드로우를 제거할 것이다. 이 과정은 Early ZS Test를 사용할 때 만큼의 퍼포먼스를 보장하지는 않지만, 2D 렌더러를 수정하는 것 보다는 쉽다.

이것을 모두 적용하면, 처음에 이 상태였던 것을

이렇게 바꿀 수 있다. 각 레이어의 불투명한 부분을 occlude로 사용해서, 장면의 overdraw 대부분을 성공적으로 제거할 수 있다. 프레임 당 오버드로우를 픽셀 당 평균 (최초 값인) 3.5에서 1.25 fragment로 줄일 수 있다.
'GPU' 카테고리의 다른 글
| Ep 2.4 : Engine and API best practices (1) | 2024.04.15 |
|---|---|
| Ep 2.2 : Best practice principles (1) | 2024.04.08 |
| Unreal에서의 GPU Crash Debugging (1) | 2023.12.17 |
| Shader Programs 최적화 (0) | 2023.09.02 |


